《Rust 实战课》学习笔记¶
以下是学习张汉东大神的Rust课程 中摘录的笔记
后续会持续更新
Rust语言版本说明¶
- Rust语言的版本包括以下三个相互正交的概念:
- 语义化版本(Sem Ver,Semantic Versioning)
- 发行版本
- Edition版次
- 语义化版本(Sem Ver, Semantic versioning)
其格式为:主版本号.次版本号.修订号
- 语义版本号递增规则:
- 主版本号:当做了不兼容的API修改;
- 次版本号:当做了向下兼容的功能性新增;
- 修订号:当做了向下兼容的问题修正;
- 发行版本
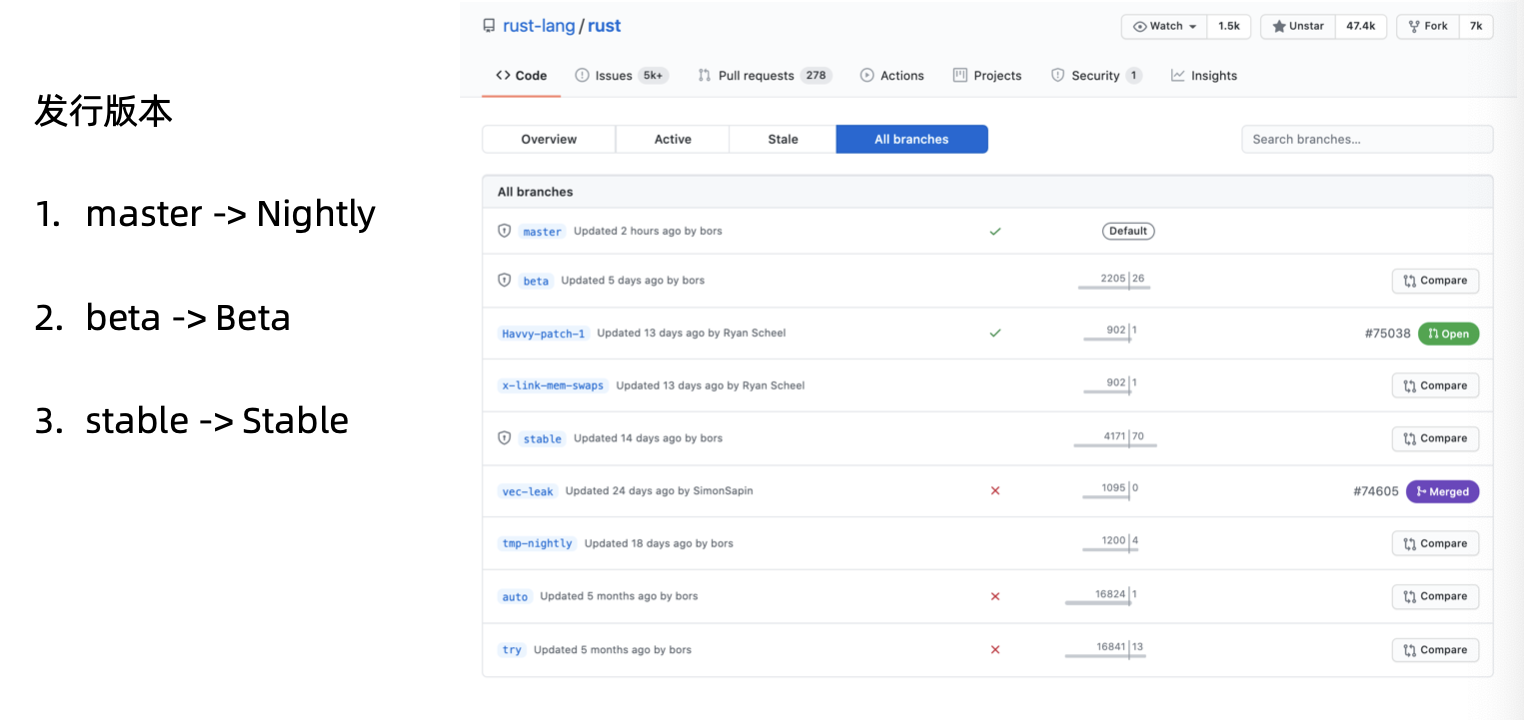
- Edition版次

Rust词法结构¶
Rust编译过程¶

Rust词法结构¶
包含其六大部分:
- 关键字(Keywords)
- 标识符(Identifier)
- 注释(Comment)
- 空白(Whitespace)
- 词条(Tokens)
- 路径(Path)
- 关键字
- 严格关键字(Strict)
- as/ break/ const/ continue/ crate/ if/ else/ struct/ enum/ true/ false/ fn/ for/ in/ let/ loop/ impl/ mod/ match/ move / mut /pub/ ref/ return/ self/ Self/ static/ super/ trait/ type/ unsafe/ use/ where/ while /async/ await/ dyn / main
- 保留字(Reserved)
- abstract/ become/ box/ do/ final/ macro/ override/ priv/ typeof/ unsized/ virtual/ yield / try
- 被保留的关键字不代表将来一定会使用
- 弱关键字(Weak)
- 2018 Edition: union, ‘static
- 2015 Edition: dyn
- 被保留的关键字不代表将来一定会使用
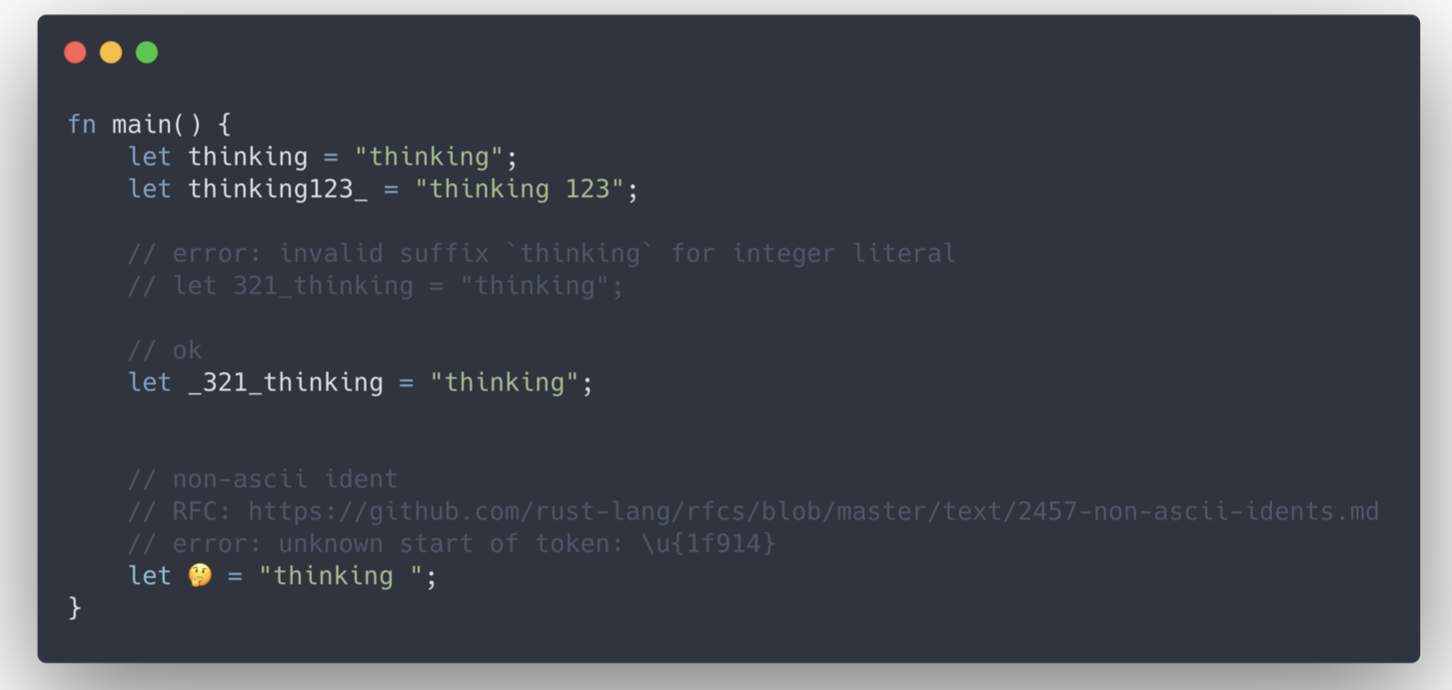
- 标识符
- 注释


- 空白
- Rust中空白字符包括:
\n、\t、tab等; - 任何形式的空白字符在 Rust 中只用于分隔标记,无语义意义;
- 词条
- 语言项(item)
- 块(block)
- 语句(Stmt)
- 表达式 (Expr)
- 模式(Pattern)
- 关键字(Keyword)
- 标识符(Ident)
- 字面量(Literal)
- 生命周期(Lifetime)
- 可见性(Vis)
- 标点符号(Punctuation)
- 分隔符(delimiter)
- 词条树(Token Tree)
- 属性(Attribute)
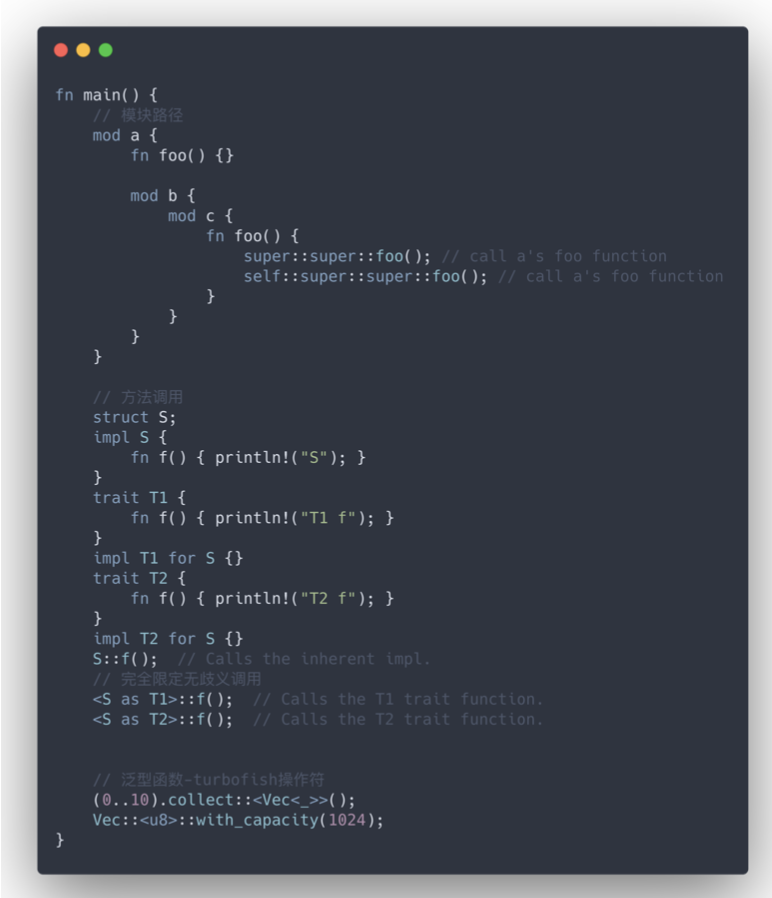
- 路径
Rust语法面面观:面向表达式¶
表达式和语句¶
表达式和语句中的广义视角:每行代码都可以看作是一个语句。
语句的四种类型:
- 声明语句
- 流程控制语句
- 表达式语句
- 宏语句
Rust 语法的“骨架”可以缩为一行,并最终可以简化为三个关键元素:
- 属性,类似于
#![...]; - 分号
;即行分隔符; - 花括号
{...}即块分隔符;
Rust 为面向表达式的语言,借鉴了函数式语言,面向表达式。
面向表达式¶
- 分号和块是 Rust 语言的两个基本表达式。
-
分号表达式
- 单元类型(Unit Type)
; -> () -
块表达式
- 块中最后一个表达式的值
- Rust 中的求值规则:
- 分号表达式返回值永远为自身的单元(Unit)类型:
(); - 分号表达式只有在块表达式最后一行才会进行求值,其他时候只作为连接符存在;
- 块表达式只对其最后一行表达式进行求值;
- 验证求值规则
- 另一种划分方式
- 基本语句
- 声明语句
- 表达式语句
- 表达式
- 块中最后一行不加分号的表达式
流程控制也是表达式。
除了基本的声明语句,其他皆为表达式。
编译期计算¶
编译期计算:最先由 Lisp/Cpp 语言支持,CTFE(compile time function evaluation)。
编译期计算 Rust 支持两种方式:
- 过程宏 + Build 脚本(build.rs)
- 类似于 Cpp 中 constexpr 的 CTFE 功能
Rust 中的 CTFE:
- 常量函数(const fn)
- 常量泛型(const generic)
常量函数 const fn¶
常量表达式与常量上下文:

fn main(){
let an = (42,).0;
const AN:i32 = an; // Error: attempt to use a non-constant value in a constant
// fixed error:
const AN:i32 = (42,).0;
}
常量上下文(const context)包含:
- 常量值初始化位置
- 静态数组的长度表达式,[T; N]
- 重复的长度表达式,类似于:[0; 10]
- 静态变量、枚举判别式的初始化位置
我们需要注意:
- 常量上下文是编译器唯一运行进行编译期求值的地方
- 在非常量上下文的地方,常量表达式不一定会在编译期求值
常量传播(Const Propagation)¶
常量传播和编译期计算是不同的:
- 常量传播是编译器的一种优化;
- 常量传播并不能改变程序的任何行为,并且对开发者是隐藏的;
- 编译期计算则是指编译时执行的代码,必须知道其结果,才能继续执行;
常量安全(Const Safe)¶
- Rust 里的大部分表达式都可用作常量表达式;
- 并不是所有常量表达式都可以用在常量上下文;
- 编译期求值必须得到一个确定性的结果;
const fn gcd(a:u32,b:u32)->u32{
match (a,b) {
(x,0)|(0,x) => x,
(x,y) if x % 2 == 0 && y % 2 ==0 => 2 * gcd(x/2,y/2),
(x,y) | (y,x) if x % 2 == 0 => gcd(x/2,y),
(x,y) if x < y => gcd((y-x)/2,x),
(x,y) => gcd((x-y)/2,y),
}
}
const GCD : u32 = gcd(21,7);
fn main() {
println!("{}",GCD);
}
const fn fib(n:u128)->u128{
const fn helper(n:u128,a:u128,b:u128,i:u128)->u128{
if i<=n {
helper(n,b,a+b,i+1)
}else{
b
}
}
helper(n,1,1,2)
}
const X:u128 = fib(10);
fn main() {
println!("{}",GCD);
}
常量安全子类型系统:
- 普通的 fn 关键字定义的函数,是 Safe Rust 主类型系统保证安全。
- const fn 定义的函数,是 Safe Rust 主类型系统下有一个专门用于常量计算的子类型系统来保证常量安全。
常量上下文可接受的常量表达式¶
- const fn 函数
- 元组结构体
- 元组的值
// Error
const fn hello()->String{
"Hello".to_string()
}
// Error
const S : String = hello();
// Correct
const fn hello()->&'static str{
"Hello"
}
// Correct
const Y: &str = hello();
fn main(){
println!("{:?}",S);
}
#[derive(Debug)]
struct Answer(u32);
const A:Answer = Answer(42);
fn main(){
println!("{}",A);
}
编译期计算如何实现¶
- MIR(中级中间语言)
- Miri(编译期内置 MIR 解释器)
比如下面的代码在编译期:
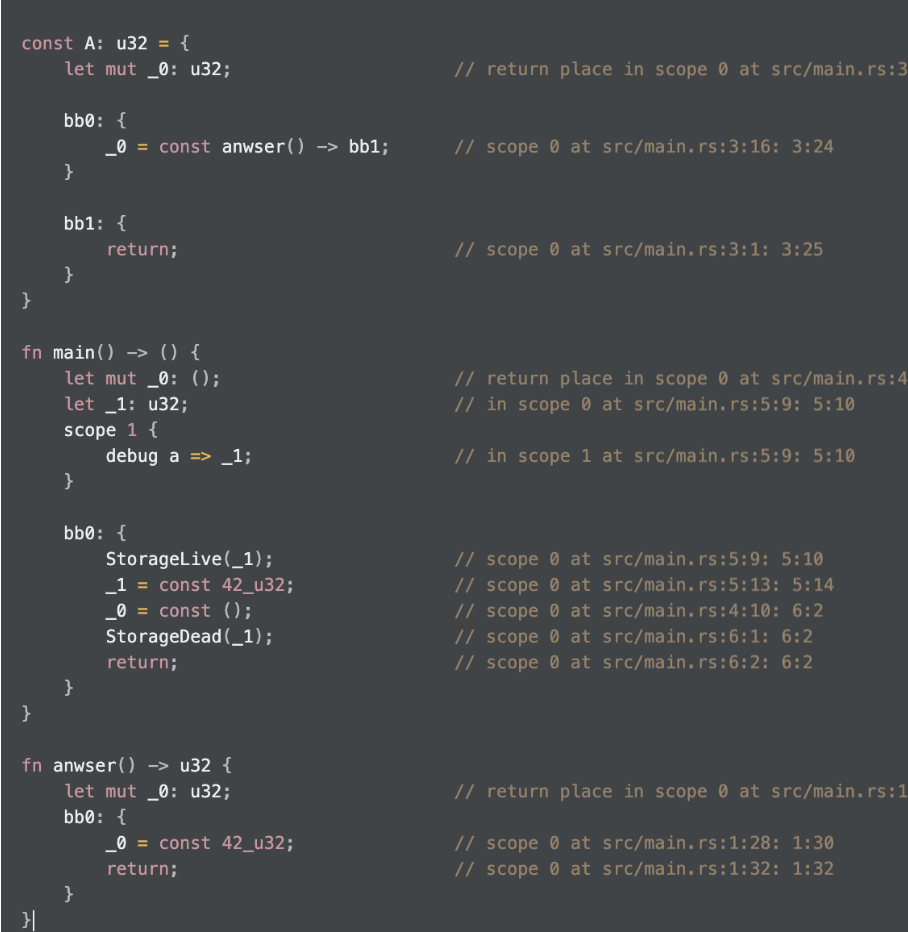
其 Miri 中求值主要过程为:
- const A 赋值
- 在 bb0 中调用 const answer
- const answer 返回常量 42
- 流程跳到 bb1
- 返回42
While true vs loop¶
- 想使用无限循环的时候建议使用 loop,而非 while true
关于编译期为什么不识别 while true 主要有以下原因:
- 要考虑:
while(constexpr = true)的情况; - 使用
#[allow(while_true)]属性在某些情况下允许使用 while true(上面的例子不符合使用情况);
常量泛型 const generic¶
Rust 中的静态数组一直以来都属于“二等公民”,不方便使用。
#![feature(min_const_generics)]
use core::mem::MaybeUninit;
const X:u128 = fib(10);
pub struct ArrayVec<T, const N: usize> {
items: [MaybeUninit<T>; N],
length: usize,
}
目前存在的缺陷:
- 目前仅限于整数原生类型,包括有符号和无符号整数类型,布尔值和字符还不允许使用复合类型和自定义类型,也不允许使用引用,即意味着不允许使用字符串;
- 常量泛型参数目前只支持两种表达式: - 一个简单的常量泛型参数 - 可以在不依赖于任何类型或常量参数的常量上下文中使用的表达式
类型理论¶
常量泛型是一种依赖类型(Depended Type)
因为数组 [T;N] 的类型,最终是要依赖于 N 的具体值来确定。
#![feature(min_const_generics)]
#![feature(const_in_array_repeat_expressions)]
use core::mem::MaybeUninit;
#[derive(Debug)]
pub struct ArrayVec<T, const N: usize> {
items: [MaybeUninit<T>; N],
length: usize,
}
impl<T,const N:usize> ArrayVec<T,{N}>{
pub const fn new()->ArrayVec<T,{N}>{
ArrayVec{
items:[MaybeUninit::uninit();N],
length:0,
}
}
#[inline]
pub const fn len(&self) -> usize { self.length}
#[inline]
pub const fn is_empty(&self) -> bool { self.len() == 0}
#[inline]
pub const fn capacity(&self) -> usize { N}
#[inline]
pub const fn is_full(&self) -> bool { self.len() >= self.capacity()}
}
从表达式的分类角度来看 Rust 的变量绑定和引用¶
Rust 中表达式的分类¶
- 位置表达式&值表达式

- 表达式背后的内存管理

- let 绑定
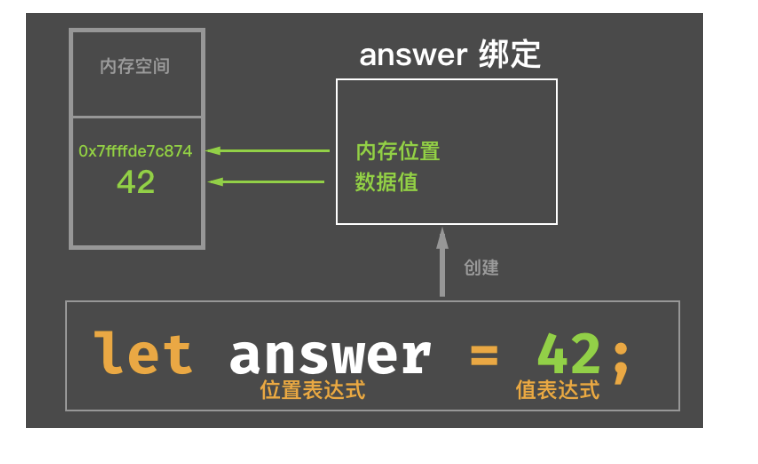
- 位置表达式包括以下:
- 静态变量初始化:
static mut LEVELS:u32 = 0;
- 解引用表达式:
*expr
- 数组索引表达:
express[expr]
- 字段表达式:
expr.field
- 以及上述加上括号的位置表达式:
(expr)
除此之外的都是值表达式。
- 位置上下文
- 除了赋值左侧的位置上下文之外,还有复合赋值操作的左侧;
- 一元借用和解引用操作中的操作数所在区域;
- 字段表达式的操作数所在区域
- 数组索引表达式的操作数所在区域
- 任意隐式借用操作数所在区域
- let 语句初始化
- if let / while let / match 的匹配表达式所在区域
let dish = {"Ham","Eggs"};
if let ("Bacon", b) = dish{ // 匹配表达式所在区域就是位置上下文
println!("Bacon is serverd with {}",b);
} else {
println!("No bacon will be served");
}
// while let (位置上下文) = ... { ... }
// match (位置上下文) { ... }
- 结构体更新语法中的 base 表达式(
..操作符后面的操作数区域)
let mut base = Point3d{x:1,y:2,z:3};
let y_ref = &mut base.y;
Point3d{y:0,z:10,..base}; // 得到 base.x
Rust 所有权语义在表达式上的体现¶
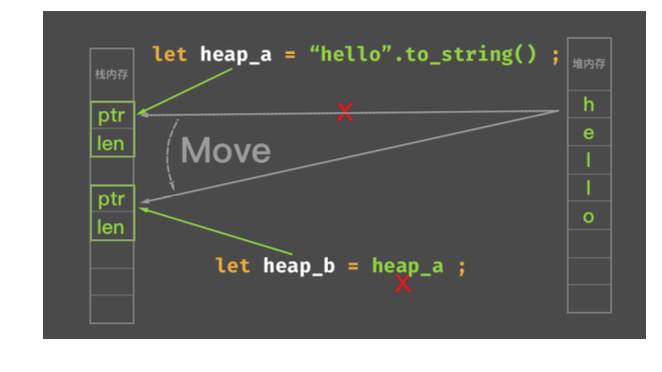
- Copy 语义代表可以安全在栈内存复制

- Move 语义代表必须旧的绑定失效,避免内存不安全
不可变与可变¶
Rust 借鉴了函数式语言的不可变特性,包括:
- 不可变绑定与可变绑定
- 不可变引用与可变引用
- 不可变绑定与可变绑定
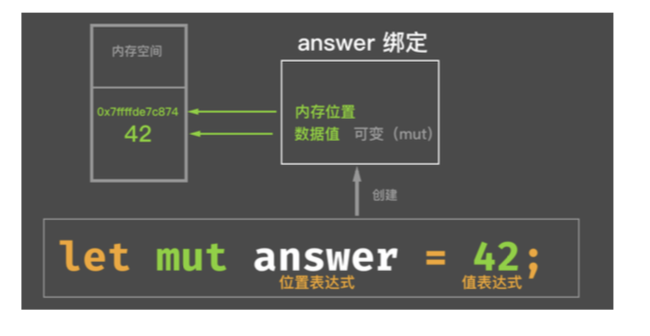
默认不可变:

如果想修改变量的值:
可变绑定使用 mut 修饰符:
- 不可变引用与可变引用
不可变引用也叫做共享引用:

同样可变引用使用 mut 修饰引用:
可变引用也叫独占引用:

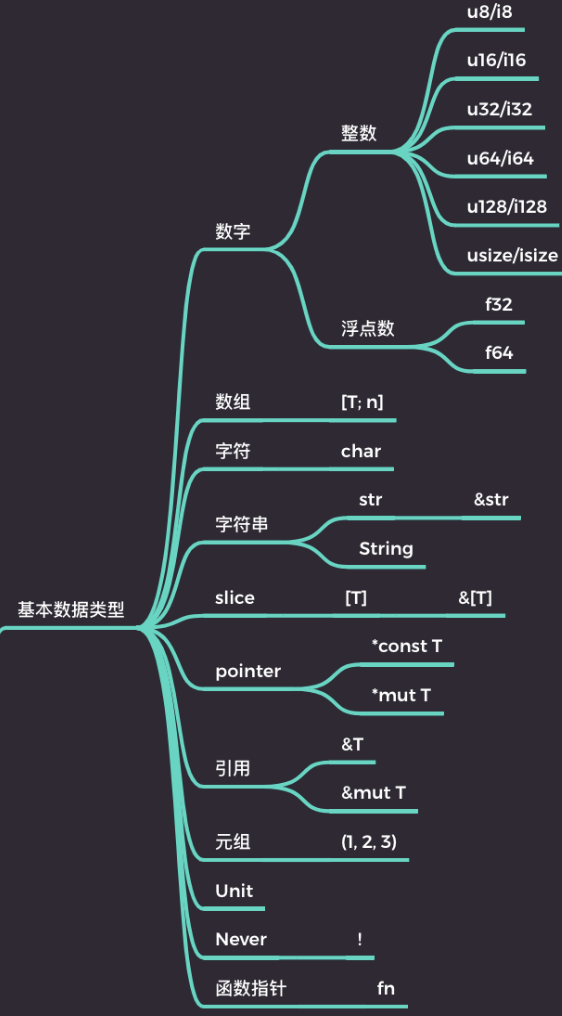
数据类型¶
基本数据类型¶
字符串¶
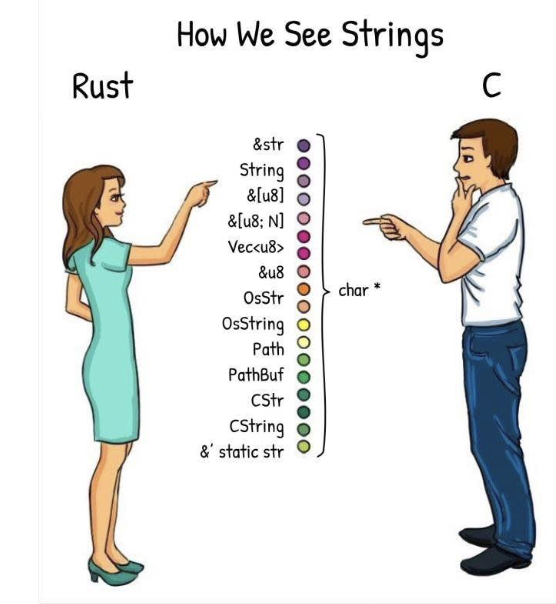
字符串为实际存在的 UNIQUE 的字符,占四个字节。
根据字符串使用场景设计类型:
- 字面量
- 动态可增长字符串
- 从一段字符串中截取的片段
- 字符串编码
- FFi 中需要转换字符串到 C 或 OS 本地字符串
- 遵循特定格式的文件路径
字符类型众多就是为了保证覆盖到所有场景且为了保证类型安全。
字符串与切片¶
字符串为 UTF-8 编码的 u8 序列。但 u8 序列切片并不一定是合法的字符串切牌呢。
Rust 内存分配默认是在栈上分配内存,并且通过栈来管理堆内存,所以必须在编译期来确定类型的大小。但编译期不可能知道开发者字符串的长度,所以这里 str 类型是一个动态大小的类型。
- str -> &str
这类引用被称为胖指针,它表示栈上存储一个指向静态区域或者是堆内存的指针。以及数据的长度,它比普通指针占用的空间更大,所以叫做胖指针。字符串可以存储于静态存储区,栈内存只存指针,所以它是一个静态引用字符串切片类型 。
- [T] -> &[T]
- String -> Vec
指针类型¶
三种指针类型:
- 原始指针,
*mut T和*const T; NonNull指针。它是 Rust 语言建议的*mut T指针的替代指针。NonNull指针是非空指针,并且是遵循生命周期类型协变规则。- 函数指针:函数指针是指向代码的指针,而非数据。可以使用它直接调用函数。
引用¶
两种引用类型:
&T和&mut T;- 引用与指针的主要区别:
- 引用不可能为空;
- 拥有生命周期;
- 受借用检查器保护不会发生悬垂指针等问题;
元组¶
唯一的异构序列:
- 不同长度的元组是不同类型;
- 单元类型的唯一实例等价于空元组;
- 当元组只有一个元素的时候,要在元素末尾加逗号分隔,以此方便和括号操作符区分开来。
Never 类型¶
为了保证类型安全就需要考虑所有可能的情况,所有也要考虑不可能返回值的计算情况。
代表的是不可能返回值的计算类型:
- 类型理论中叫做底类型,底类型不包含任何值,但它可以合一到任何其他类型;
- Never 类型用
!叹号表示; - 目前还未稳定,但在 Rust 内部已经在使用了;
自定义复合类型¶
- 结构体 Struct
- 枚举体 Enum
- 联合体 Union
分别有具名结构体、元组结构体、单元结构体。
// 具名结构体,包含了字段
struct Point{
x: f32,
y: f32,
}
// 元组结构体
struct Pair(i32, f32);
// 单元结构体
struct Unit;
fn main(){
let point = Point{x:1.0, y:2.0};
let pair = Pair(1, 2.0);
assert_eq!(pair.0, 1);
let unit1 = Uint;
let unit2 = Unit;
}
当元组结构体只包含一个成员时:
struct Score(u32);
impl Score{
fn pass(&self) -> bool{
self.0>=60
}
}
fn main(){
let s = Score(50);
assert_eq!(s.pass(), false)
}
对于结构体内存布局方面,编译器会对结构体进行内存对齐,以此提升 CPU 的访问效率。使用内存布局属性可以指定 C 内存布局,防止编译器重排。
struct A{
a: u8,
b: u32,
c: u16,
}
// 编译器重排字段,优化内存占用
//struct A{
// a: u32,
// b: u16,
// c: u8,
//}
// 8
//#[repr(C)]
//struct A{
// a: u8,
// b: u32,
// c: u16,
//}
// 12
fn main(){
println!("{:?}",std::mem::size_of::<A>()); // 8
let v = A{a:1, b:2, c:3 };
}
枚举体与联合体内存布局中,以枚举类型成员最大的对齐值为准不需要为每个枚举值都对齐。
enum A {
One,
Two,
}
enum E {
N,
H(u32),
M(Box<u32>)
}
union U{
u: u32,
v: u64
}
fn main(){
println!("E: {:?}",std::mem::size_of::<A>()); // 1
println!("Box<u32>: {:?}",std::mem::size_of::<Box<u32>>()); // 8
println!("U: {:?}",std::mem::size_of::<E>()); // 16
println!("U: {:?}",std::mem::size_of::<U>()); // 8
}
容器类型¶
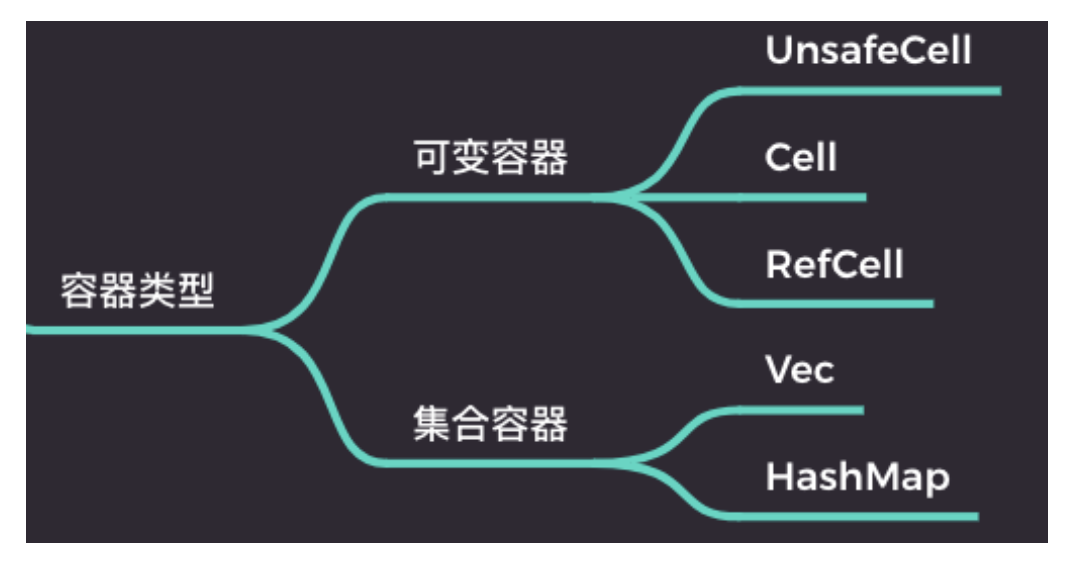
内部可变性(interior mutability)¶
- 与继承式可变相对应;
- 由可变性核心原语 UnsafeCell
提供支持; - 基于 UnsafeCell
提供了 Cell 和 RefCell 。
Cell & RefCell¶
use std::cell::Cell;
struct Foo {
x: u32,
y: Cell<u32>
}
fn main(){
let foo = Foo {x: 1, y: Cell::new(3)};
assert_eq!(1, foo.x);
assert_eq!(3, foo.y.get());
foo.y.set(5);
assert_eq!(5, foo.y.get());
let s = "hello".to_string();
let bar = Cell::new(s);
let x = bar.into_inner();
// bar; // error: use of moved value: `bar`
}
use std::cell::RefCell;
fn main(){
let x = RefCell::new(vec![1,2,3,4]);
println!("{:?}", x.borrow());
x.borrow_mut().push(5);
println!("{:?}", x.borrow());
}
- 运行时借用检查

泛型¶
所谓泛型就是参数化类型。
fn foo<T>(x: T)->T{
return x;
}
fn main(){
assert_eq!(foo(1), 1);
assert_eq!(foo("hello"), "hello");
}
- 静态分发
fn main(){
fn foo_1(x: i32)->i32{
return x;
}
fn foo_2(x:&'static' str)->&'static str{
return x;
}
foo_1(1);
foo_2("2");
}
- 当类型推断失效,需要手工指定类型的时候使用
特定类型¶
所谓特定类型,是指专门有特殊用途的类型
- PhantomData
, 幻影类型。 一般用于 Unsafe Rust 的安全抽象。 - Pin
, 固定类型。为了支持异步开发而特意引进,防止被引用的值发生移动的类型。