Bonus Unit 2. Agent Observability and Evaluation¶
Observability 基础¶
1. 什么是智能体可观察性?
智能体可观察性是指通过外部信号(如日志、指标和轨迹)来理解AI智能体内部运作的能力。对于AI智能体,这意味着跟踪行动、工具使用、模型调用和响应,以便调试和改进智能体性能。
可观察性使智能体从"黑盒"变为透明系统,让开发者能够:
- 理解成本与准确性的权衡
- 测量延迟情况
- 检测有害语言和提示注入
- 监控用户反馈
2. 可观察性工具与标准
| 工具类型 | 代表性平台 | 特点 |
|---|---|---|
| 开源平台 | Langfuse | 社区驱动、广泛集成 |
| 商业平台 | Arize | 提供专业仪表盘和实时监控 |
| 技术标准 | OpenTelemetry | 多框架支持的可观察性标准 |
大多数智能体框架(如smolagents)使用OpenTelemetry标准向可观察性工具暴露元数据。此外,可观察性工具还构建自定义检测工具,以在快速发展的LLM领域提供更大的灵活性。
3. 轨迹和跨度
可观察性工具通常将智能体运行表示为轨迹和跨度: - 轨迹(Traces):表示从开始到结束的完整智能体任务(如处理用户查询) - 跨度(Spans):轨迹内的单个步骤(如调用语言模型或检索数据)
关键监控指标¶
1. 延迟(Latency)
- 定义:智能体响应的速度
- 重要性:长等待时间会对用户体验产生负面影响
- 测量方法:通过跟踪智能体运行来测量任务和单个步骤的延迟
- 优化示例:使用较快的模型或并行运行模型调用
2. 成本(Costs)
- 定义:每次智能体运行的费用
- 组成部分:LLM调用(按token计费)和外部API使用费用
- 监控目的:识别不必要的调用或选择更经济的模型
- 警示情况:监控意外的成本激增(如导致过度API循环的bug)
3. 请求错误(Request Errors)
- 定义:智能体失败的请求数量
- 包括:API错误或工具调用失败
- 改进方向:设置回退或重试机制
- 示例:当提供商A宕机时,切换到备用提供商B
4. 用户反馈(User Feedback)
| 反馈类型 | 说明 | 示例 |
|---|---|---|
| 显式反馈 | 用户直接提供的评估 | 点赞/踩、星级评分、文本评论 |
| 隐式反馈 | 用户行为提供的间接反馈 | 立即重新表述问题、重复查询、点击重试按钮 |
5. 准确性(Accuracy)
- 定义:智能体产生正确或期望输出的频率
- 衡量方法:因应用场景而异(如问题解决正确性、信息检索准确性、用户满意度)
- 跟踪方式:通过自动检查、评估分数或任务完成标签
6. 自动评估指标(Automated Evaluation Metrics)
- LLM评判:使用LLM为智能体输出打分(如有用性、准确性)
- 专业库:使用如RAGAS(适用于RAG智能体)或LLM Guard(检测有害语言)等开源库
智能体评估类型¶
1. 离线评估(Offline Evaluation)
离线评估在受控环境中使用测试数据集进行,而非实时用户查询:
| 特点 | 说明 |
|---|---|
| 数据使用 | 使用已知预期输出的策划数据集 |
| 进行时机 | 开发期间(可作为CI/CD流程的一部分) |
| 主要优势 | 可重复且能获得明确的准确性指标(有基准真值) |
| 示例应用 | 数学问题求解智能体可使用100道已知答案的测试题 |
| 主要挑战 | 确保测试集全面且保持相关性 |
良好的离线评估策略通常结合"快速测试"和更大规模的评估集:小测试集用于快速检查,大测试集用于更广泛的性能指标。
2. 在线评估(Online Evaluation)
在线评估是指在实际生产环境中评估智能体:
| 特点 | 说明 |
|---|---|
| 环境 | 实时、真实世界环境中的智能体使用 |
| 监控内容 | 真实用户交互中的智能体性能与结果分析 |
| 示例指标 | 成功率、用户满意度评分或其他实时指标 |
| 主要优势 | 捕捉实验室环境中无法预见的情况 |
| 评估方法 | 收集用户反馈、运行影子测试或A/B测试 |
| 主要挑战 | 难以为实时交互获取可靠的标签或评分 |
在线评估能够观察模型随时间的漂移(如输入模式变化导致的效果降低)并捕获测试数据中未包含的意外查询或情况。
3. 综合评估策略
成功的AI智能体评估通常结合离线和在线方法:
- 通过离线基准测试定量评分智能体在特定任务上的表现
- 持续监控实时使用情况以捕捉基准测试可能遗漏的问题
- 采用迭代循环:
这种方法确保评估是持续和不断完善的过程。
实践智能体可观察性¶
1. 工具设置
首先需要安装必要的库并配置环境变量:
# 安装必要库
%pip install 'smolagents[telemetry]'
%pip install opentelemetry-sdk opentelemetry-exporter-otlp openinference-instrumentation-smolagents
%pip install langfuse datasets 'smolagents[gradio]'
# 配置环境变量(以Langfuse为例)
import os
import base64
LANGFUSE_PUBLIC_KEY = "pk-lf-..."
LANGFUSE_SECRET_KEY = "sk-lf-..."
LANGFUSE_AUTH = base64.b64encode(f"{LANGFUSE_PUBLIC_KEY}:{LANGFUSE_SECRET_KEY}".encode()).decode()
os.environ["OTEL_EXPORTER_OTLP_ENDPOINT"] = "https://cloud.langfuse.com/api/public/otel"
os.environ["OTEL_EXPORTER_OTLP_HEADERS"] = f"Authorization=Basic {LANGFUSE_AUTH}"
2. 智能体检测
使用OpenTelemetry设置跟踪提供程序并对智能体进行检测:
from opentelemetry.sdk.trace import TracerProvider
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from opentelemetry import trace
# 创建跟踪提供程序
trace_provider = TracerProvider()
trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
trace.set_tracer_provider(trace_provider)
tracer = trace.get_tracer(__name__)
# 检测smolagents
SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
3. 测试检测
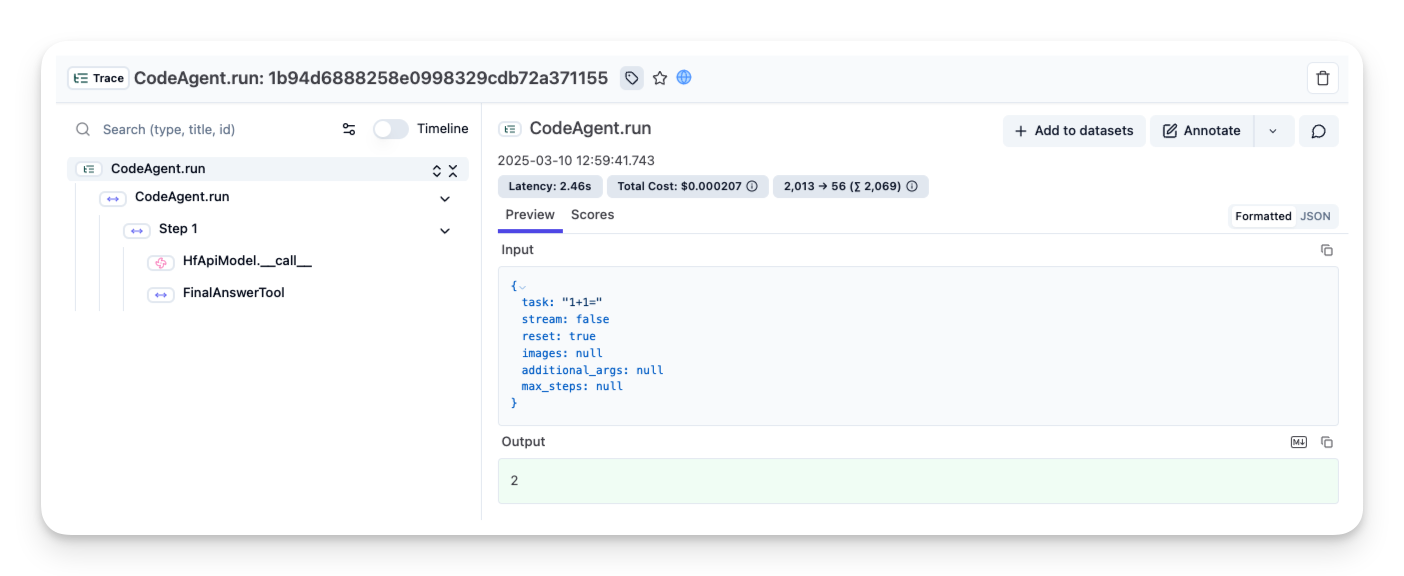
创建并运行简单智能体验证检测是否正常工作:
from smolagents import InferenceClientModel, CodeAgent
# 创建简单智能体进行测试
agent = CodeAgent(
tools=[],
model=InferenceClientModel()
)
agent.run("1+1=")
成功设置后,可观察性工具中将显示日志和跟踪数据。
4. 在线评估示例
4.1 成本指标
可观察性工具可显示每个模型调用的token用量和相关成本:
from smolagents import CodeAgent, DuckDuckGoSearchTool, InferenceClientModel
search_tool = DuckDuckGoSearchTool()
agent = CodeAgent(tools=[search_tool], model=InferenceClientModel())
agent.run("How many Rubik's Cubes could you fit inside the Notre Dame Cathedral?")
4.2 延迟指标
跟踪工具可分解整个会话所需时间,帮助识别瓶颈:
4.3 添加自定义属性
可使用OpenTelemetry为跨度添加自定义属性(如用户ID、会话ID或标签):
from opentelemetry import trace
with tracer.start_as_current_span("Smolagent-Trace") as span:
span.set_attribute("langfuse.user.id", "user-123")
span.set_attribute("langfuse.session.id", "session-123456789")
span.set_attribute("langfuse.tags", ["city-question", "testing-agents"])
agent.run("What is the capital of Germany?")
4.4 用户反馈集成
使用Gradio创建包含反馈机制的聊天界面:
import gradio as gr
from opentelemetry.trace import format_trace_id
from langfuse import Langfuse
langfuse = Langfuse()
formatted_trace_id = None
def respond(prompt, history):
with trace.get_tracer(__name__).start_as_current_span("Smolagent-Trace") as span:
output = agent.run(prompt)
current_span = trace.get_current_span()
span_context = current_span.get_span_context()
trace_id = span_context.trace_id
global formatted_trace_id
formatted_trace_id = str(format_trace_id(trace_id))
history.append({"role": "assistant", "content": str(output)})
return history
def handle_like(data: gr.LikeData):
# 将用户反馈映射为1(喜欢)或0(不喜欢)
if data.liked:
langfuse.score(value=1, name="user-feedback", trace_id=formatted_trace_id)
else:
langfuse.score(value=0, name="user-feedback", trace_id=formatted_trace_id)
# 创建Gradio界面
with gr.Blocks() as demo:
chatbot = gr.Chatbot(label="Chat", type="messages")
prompt_box = gr.Textbox(placeholder="输入您的消息...", label="您的消息")
prompt_box.submit(fn=respond, inputs=[prompt_box, chatbot], outputs=chatbot)
chatbot.like(handle_like, None, None)
demo.launch()
4.5 LLM评判机制
LLM评判是自动评估智能体输出的方法:
- 定义评估模板(例如:"检查文本是否有害")
- 智能体生成输出后,将该输出与模板一起传递给"评判"LLM
- 评判LLM以评分或标签形式回应,记录到可观察性工具中
5. 离线评估示例
使用GSM8K数据集进行离线评估:
from datasets import load_dataset
import pandas as pd
from langfuse import Langfuse
# 加载GSM8K数据集
dataset = load_dataset("openai/gsm8k", 'main', split='train')
df = pd.DataFrame(dataset)
# 在Langfuse中创建数据集实体
langfuse = Langfuse()
langfuse_dataset_name = "gsm8k_dataset_huggingface"
langfuse.create_dataset(
name=langfuse_dataset_name,
description="GSM8K基准数据集(从Huggingface上传)",
metadata={"date": "2023-03-10", "type": "benchmark"}
)
# 上传数据集条目
for idx, row in df.iterrows():
langfuse.create_dataset_item(
dataset_name=langfuse_dataset_name,
input={"text": row["question"]},
expected_output={"text": row["answer"]},
metadata={"source_index": idx}
)
if idx >= 9: # 仅上传前10项作为演示
break
创建辅助函数在数据集上运行智能体:
from opentelemetry.trace import format_trace_id
def run_smolagent(question):
with tracer.start_as_current_span("Smolagent-Trace") as span:
span.set_attribute("langfuse.tag", "dataset-run")
output = agent.run(question)
current_span = trace.get_current_span()
span_context = current_span.get_span_context()
trace_id = span_context.trace_id
formatted_trace_id = format_trace_id(trace_id)
langfuse_trace = langfuse.trace(id=formatted_trace_id, input=question, output=output)
return langfuse_trace, output
# 在数据集上运行智能体
dataset = langfuse.get_dataset(langfuse_dataset_name)
for item in dataset.items:
langfuse_trace, output = run_smolagent(item.input["text"])
# 将跟踪链接到数据集项目
item.link(
langfuse_trace,
run_name="smolagent-notebook-run-01",
run_metadata={"model": model.model_id}
)
# 可选:存储快速评估分数
langfuse_trace.score(
name="<example_eval>",
value=1,
comment="这是一条评论"
)
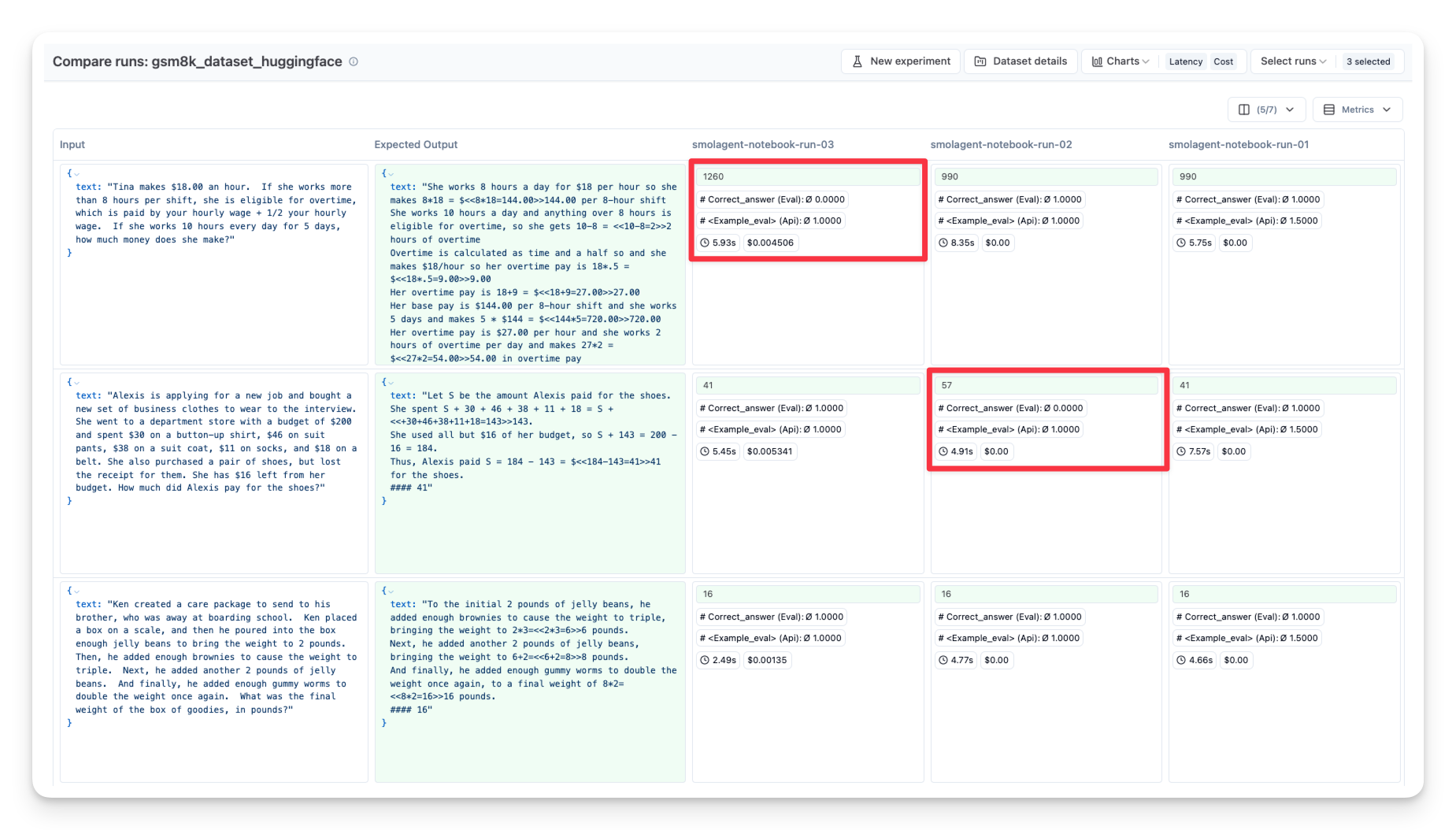
通过这种方法,可以使用不同模型、工具或提示重复评估过程,然后在可观察性工具中进行并排比较。
总结¶
智能体可观察性和评估对于构建生产级AI系统至关重要。通过结合离线和在线评估方法,开发者可以:
- 全面了解智能体性能:从多个维度(成本、延迟、准确性)评估智能体
- 持续改进:通过实时监控和用户反馈发现问题并迭代解决
- 优化资源使用:识别并减少不必要的模型调用或API请求
- 提升用户体验:确保智能体响应迅速、准确且符合预期
实施这些可观察性和评估实践使您能够将原型智能体转变为生产就绪的系统,同时保持灵活性以适应不断变化的用户需求和使用模式。