UNIT3 Use Case for Agentic RAG¶
Agentic RAG 简介¶
1. 用例背景:盛大晚会筹备
- 本用例围绕一个名为 Alfred 的智能体主持人,负责筹备并管理一场奢华的文艺复兴风格晚会
- Alfred 需要掌握菜单、宾客名单、日程安排、天气预报等各类信息
- 作为晚会主持人,Alfred 需具备实时解答问题和处理突发状况的能力
2. 晚会核心需求
| 需求类别 | 详细说明 |
|---|---|
| 知识储备 | 精通体育、文化与科学知识,展现文艺复兴教育特色 |
| 沟通限制 | 避免政治与宗教等敏感话题,保持轻松愉快的氛围 |
| 宾客了解 | 充分掌握宾客背景、兴趣爱好与事业成就,促进交流 |
| 实时信息 | 获取天气更新以把握烟花表演时机等关键决策 |
3. 为何选择 Agentic RAG
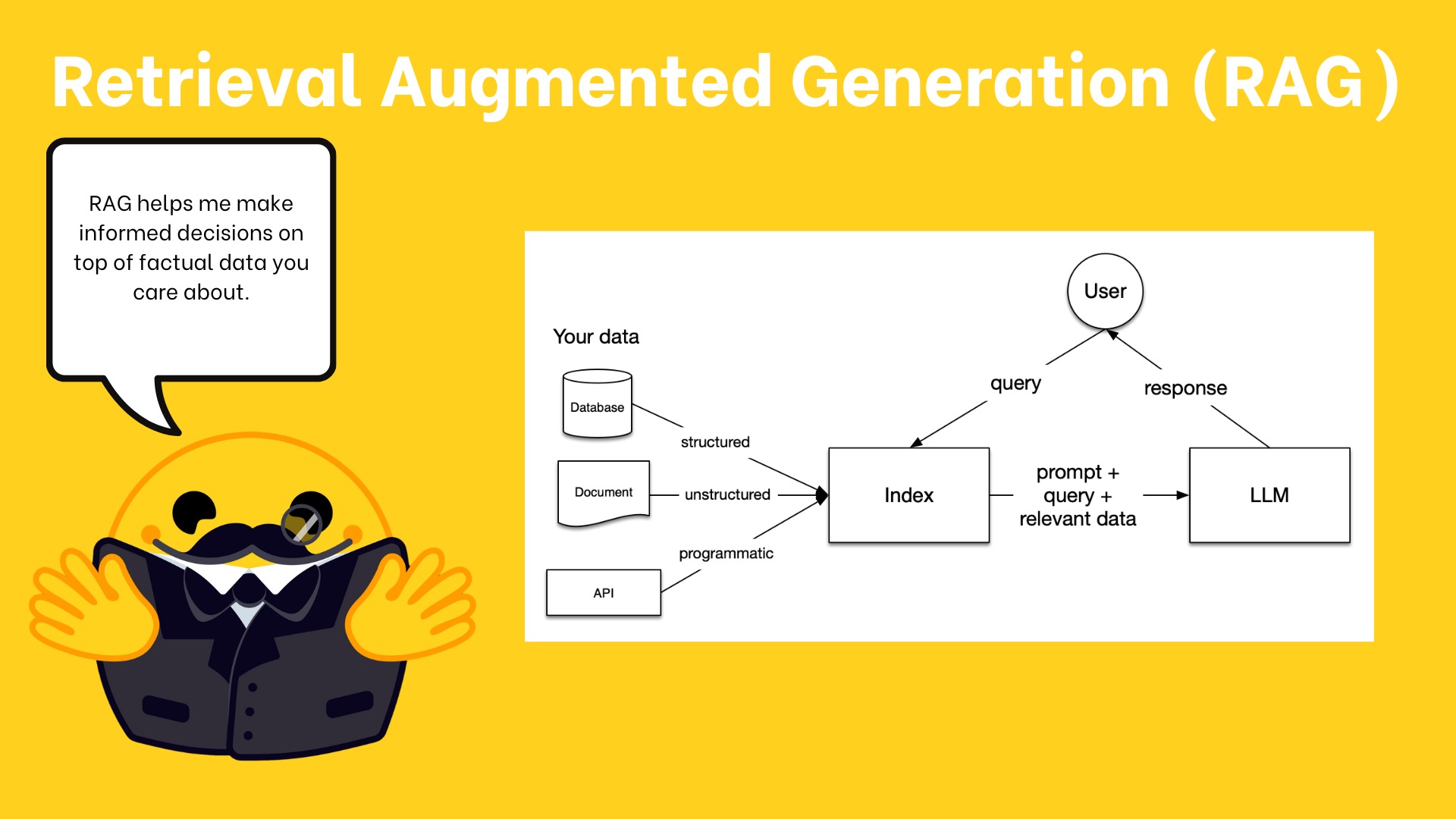
传统大语言模型在这类场景下面临的挑战:
- 宾客信息为特定活动数据,不在模型训练范围内
- 需要获取实时天气和新闻等更新信息
- 需精确检索电子邮箱等细节信息
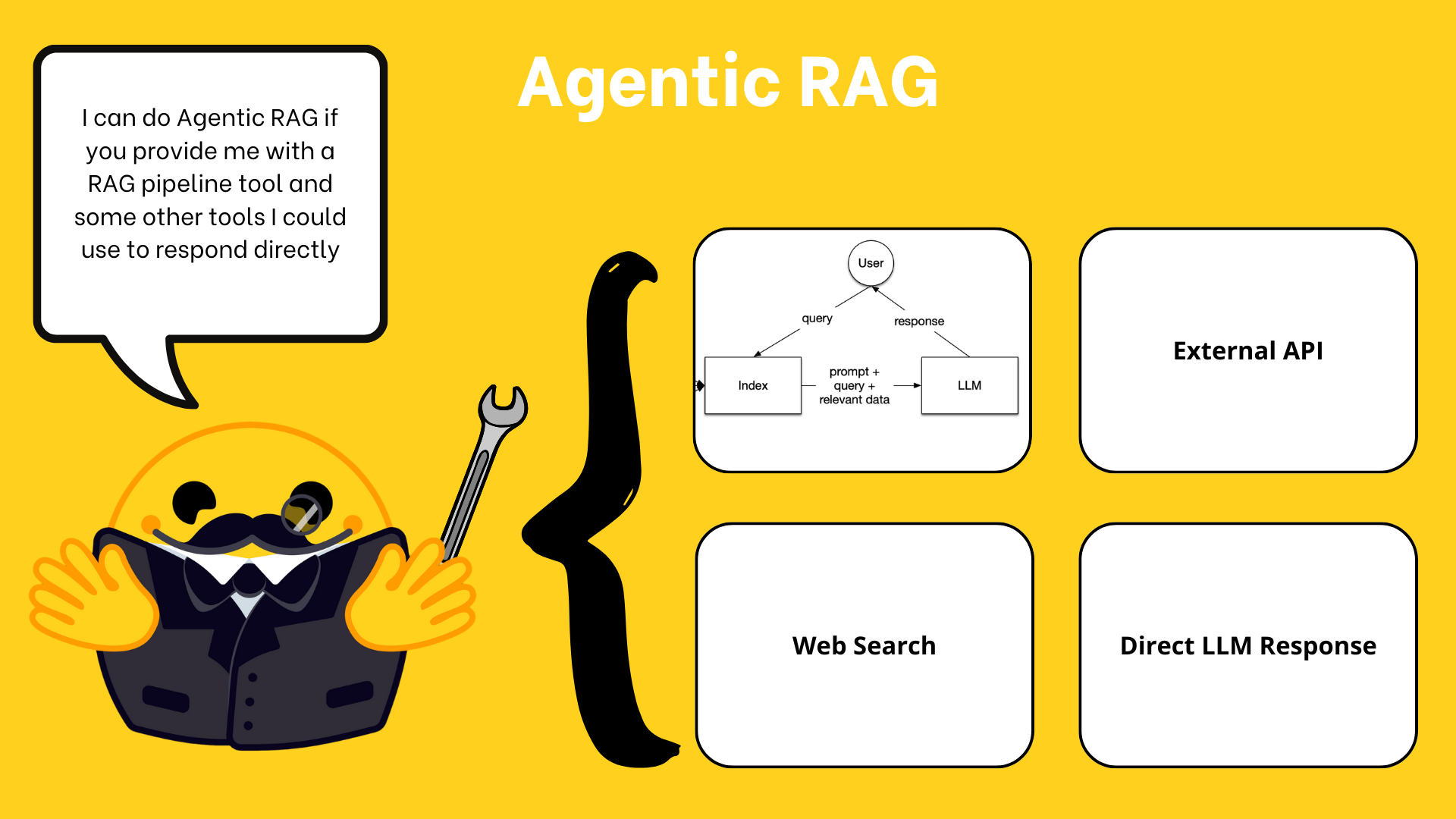
智能体增强 RAG 的优势:
- 结合检索系统与 LLM,按需获取准确、实时信息
- 智能体可自主决定使用任何工具或流程回答问题
- 整合多种信息源,提供全面、个性化响应
构建宾客信息检索工具¶
1. 数据集准备
使用 agents-course/unit3-invitees 数据集,包含以下字段:
- Name:宾客全名
- Relation:与主办方关系
- Description:简要传记或趣闻
- Email Address:联系方式
2. 检索工具实现
基于 LangGraph 实现宾客信息检索工具的核心步骤:
Python
import datasets
from langchain.docstore.document import Document
from langchain_community.retrievers import BM25Retriever
from langgraph.graph import StateGraph, START, END
from langgraph.pregel import Pregel
from langgraph.parsing import TypedConfig
# 加载数据集并转换为文档格式
guest_dataset = datasets.load_dataset("agents-course/unit3-invitees", split="train")
docs = [
Document(
page_content="\n".join([
f"Name: {guest['name']}",
f"Relation: {guest['relation']}",
f"Description: {guest['description']}",
f"Email: {guest['email']}"
]),
metadata={"name": guest["name"]}
)
for guest in guest_dataset
]
# 创建检索节点
class RetrieverNode(TypedConfig):
def __init__(self, docs):
self.retriever = BM25Retriever.from_documents(docs)
def __call__(self, state):
query = state.get("query", "")
results = self.retriever.get_relevant_documents(query)
return {"results": "\n\n".join([doc.page_content for doc in results[:3]])}
# 创建决策节点
def decide_node(state):
if "results" in state and state["results"]:
return END
else:
return "fallback"
# 创建图结构
graph = StateGraph()
graph.add_node("retriever", RetrieverNode(docs))
graph.add_node("decide", decide_node)
graph.add_node("fallback", lambda state: {"results": "No matching guest information found."})
# 定义图连接
graph.add_edge(START, "retriever")
graph.add_edge("retriever", "decide")
graph.add_edge("decide", "fallback")
graph.add_edge("fallback", END)
# 编译图
guest_info_tool = graph.compile()
3. 工具使用示例
Python
# 示例查询
response = guest_info_tool.invoke({"query": "Lady Ada Lovelace"})
print(response["results"])
# 预期输出
# Name: Lady Ada Lovelace
# Relation: Respected Mathematician and Friend
# Description: Known for her pioneering work in mathematics and computing, Lady Ada Lovelace is widely regarded as the first computer programmer for her work on Charles Babbage's Analytical Engine.
# Email: ada.lovelace@example.com
构建并集成外部工具¶
为了让 Alfred 成为全能型主持人,需要为其增加多种外部工具:
1. 网络搜索工具
实现实时网络搜索功能,使 Alfred 能获取全球最新资讯:
Python
from langgraph.graph import StateGraph, START, END
from langgraph.pregel import Pregel
from langgraph.parsing import TypedConfig
import requests
class WebSearchNode(TypedConfig):
def __call__(self, state):
query = state.get("query", "")
# 简化的网络搜索实现
search_results = f"Search results for: {query}"
return {"search_results": search_results}
# 创建并编译工具
search_graph = StateGraph()
search_graph.add_node("search", WebSearchNode())
search_graph.add_edge(START, "search")
search_graph.add_edge("search", END)
search_tool = search_graph.compile()
2. 天气信息工具
帮助 Alfred 决定烟花表演时机的工具:
Python
import random
from langgraph.graph import StateGraph, START, END
from langgraph.parsing import TypedConfig
class WeatherNode(TypedConfig):
def __call__(self, state):
location = state.get("location", "")
# 虚拟天气数据
weather_conditions = [
{"condition": "Rainy", "temp_c": 15},
{"condition": "Clear", "temp_c": 25},
{"condition": "Windy", "temp_c": 20}
]
data = random.choice(weather_conditions)
return {"weather": f"Weather in {location}: {data['condition']}, {data['temp_c']}°C"}
# 创建并编译工具
weather_graph = StateGraph()
weather_graph.add_node("weather", WeatherNode())
weather_graph.add_edge(START, "weather")
weather_graph.add_edge("weather", END)
weather_tool = weather_graph.compile()
3. Hub 统计工具
为与会的 AI 开发者提供其模型下载量信息:
Python
from langgraph.graph import StateGraph, START, END
from langgraph.parsing import TypedConfig
from huggingface_hub import list_models
class HubStatsNode(TypedConfig):
def __call__(self, state):
author = state.get("author", "")
try:
models = list(list_models(author=author, sort="downloads", direction=-1, limit=1))
if models:
model = models[0]
return {"hub_stats": f"The most downloaded model by {author} is {model.id} with {model.downloads:,} downloads."}
else:
return {"hub_stats": f"No models found for author {author}."}
except Exception as e:
return {"hub_stats": f"Error fetching models for {author}: {str(e)}"}
# 创建并编译工具
hub_stats_graph = StateGraph()
hub_stats_graph.add_node("hub_stats", HubStatsNode())
hub_stats_graph.add_edge(START, "hub_stats")
hub_stats_graph.add_edge("hub_stats", END)
hub_stats_tool = hub_stats_graph.compile()
创建完整智能体¶
1. 组装 Alfred 智能体
整合所有工具创建完整的 Alfred 智能体:
Python
from langgraph.graph import StateGraph, START, END
from langgraph.pregel import Pregel
from langgraph.parsing import TypedConfig
from typing import Dict, Any, Optional, List
# 导入先前创建的工具
from retriever import guest_info_tool
from tools import search_tool, weather_tool, hub_stats_tool
# 定义输入解析节点
class InputParserNode(TypedConfig):
def __call__(self, state):
query = state.get("query", "")
# 简单的工具选择逻辑
if "guest" in query.lower() or "who is" in query.lower():
return {"tool": "guest_info", "tool_input": query}
elif "weather" in query.lower():
location = "Paris" # 简化示例,实际应从查询中提取
return {"tool": "weather", "tool_input": {"location": location}}
elif "model" in query.lower() or "download" in query.lower():
author = "facebook" # 简化示例,实际应从查询中提取
return {"tool": "hub_stats", "tool_input": {"author": author}}
else:
return {"tool": "search", "tool_input": {"query": query}}
# 定义工具路由节点
class ToolRouterNode(TypedConfig):
def __call__(self, state):
tool = state.get("tool", "")
tool_input = state.get("tool_input", {})
if tool == "guest_info":
result = guest_info_tool.invoke({"query": tool_input})
return {"tool_output": result.get("results", "")}
elif tool == "weather":
result = weather_tool.invoke(tool_input)
return {"tool_output": result.get("weather", "")}
elif tool == "hub_stats":
result = hub_stats_tool.invoke(tool_input)
return {"tool_output": result.get("hub_stats", "")}
elif tool == "search":
result = search_tool.invoke(tool_input)
return {"tool_output": result.get("search_results", "")}
return {"tool_output": "No relevant information found."}
# 定义响应生成节点
class ResponseNode(TypedConfig):
def __call__(self, state):
query = state.get("query", "")
tool_output = state.get("tool_output", "")
# 生成响应(在实际系统中,这里会使用LLM)
response = f"🎩 Alfred's Response:\n\nRegarding your question about '{query}':\n\n{tool_output}"
return {"response": response}
# 创建 Alfred 智能体图
alfred_graph = StateGraph()
alfred_graph.add_node("input_parser", InputParserNode())
alfred_graph.add_node("tool_router", ToolRouterNode())
alfred_graph.add_node("response_generator", ResponseNode())
# 定义图连接
alfred_graph.add_edge(START, "input_parser")
alfred_graph.add_edge("input_parser", "tool_router")
alfred_graph.add_edge("tool_router", "response_generator")
alfred_graph.add_edge("response_generator", END)
# 编译 Alfred 智能体
alfred = alfred_graph.compile()
2. 使用 Alfred:端到端示例
Alfred 能够处理各种晚会相关查询,以下是几个示例场景:
Python
# 示例1:查询宾客信息
response = alfred.invoke({"query": "Tell me about Lady Ada Lovelace"})
print(response["response"])
# 示例2:查询天气信息(为烟花表演)
response = alfred.invoke({"query": "What's the weather like in Paris tonight? Will it be suitable for our fireworks display?"})
print(response["response"])
# 示例3:查询模型信息(为AI研究者)
response = alfred.invoke({"query": "One of our guests is from Qwen. What can you tell me about their most popular model?"})
print(response["response"])
# 示例4:组合多工具场景
response = alfred.invoke({"query": "I need to speak with Dr. Nikola Tesla about recent advancements in wireless energy. Can you help me prepare for this conversation?"})
print(response["response"])
3. 高级功能:对话记忆
实现对话历史记忆,使 Alfred 能够记住之前的交流:
Python
from typing import List, Dict
class MemoryManager:
def __init__(self):
self.history = []
def add_interaction(self, query, response):
self.history.append({"query": query, "response": response})
def get_context(self, max_turns=3):
return self.history[-max_turns:] if len(self.history) > 0 else []
# 修改响应生成节点以使用记忆
class MemoryEnabledResponseNode(TypedConfig):
def __init__(self, memory_manager):
self.memory = memory_manager
def __call__(self, state):
query = state.get("query", "")
tool_output = state.get("tool_output", "")
context = self.memory.get_context()
# 使用对话历史生成更个性化的响应
if context:
# 在实际系统中,这里会将上下文传递给LLM
response = f"🎩 Alfred's Response (with memory):\n\nRegarding your question about '{query}':\n\n{tool_output}"
else:
response = f"🎩 Alfred's Response:\n\nRegarding your question about '{query}':\n\n{tool_output}"
self.memory.add_interaction(query, response)
return {"response": response}
总结¶
通过本单元的学习,我们成功构建了 Alfred——一个配备多种工具的智能体助手,具备以下核心能力:
- 检索嘉宾信息:通过自定义 RAG 系统快速获取宾客详情
- 获取实时信息:利用网络搜索工具获取最新资讯
- 查询天气状况:通过天气工具合理安排户外活动(如烟花表演)
- 提供模型统计:为 AI 开发者提供其模型下载量信息
- 维持对话上下文:通过记忆功能保持连贯交流
这种智能体增强 RAG 方案展示了如何将检索系统与智能体能力结合,创建能够访问结构化知识、获取实时信息、使用专业工具并保持历史交互记忆的完整系统。
这种架构可以轻松适应各种实际应用场景,从客户服务到数据分析,从内容创建到知识管理,展现了 AI 智能体系统的强大潜力。