UNIT2.3 LangGraph Frameworks¶
1. LangGraph 简介¶
LangGraph 是由 LangChain 开发的框架,用于管理集成 LLM 的应用程序的控制流。它是一个通过提供对智能体流程的控制工具,帮助构建生产就绪应用程序的框架。
1. LangGraph 与 LangChain 的区别:
| LangChain | LangGraph |
|---|---|
| 提供与模型和其他组件交互的标准接口 | 用于管理应用程序的控制流 |
| 用于检索、LLM调用和工具调用 | 用于定义复杂工作流和状态管理 |
两个框架是独立的,可以单独使用,但在实际应用中通常会同时使用这两个包。
2. 适用场景
LangGraph 在控制与自由度的权衡中倾向于提供更多控制能力。
3. LangGraph 适用的关键场景
- 多步骤推理过程 - 需要显式控制流程
- 状态持久化 - 需要在步骤之间保持状态
- 混合系统 - 结合确定性逻辑与AI能力
- 人工介入 - 需要人类参与的工作流
- 复杂智能体架构 - 多个组件协同工作
4. 示例场景
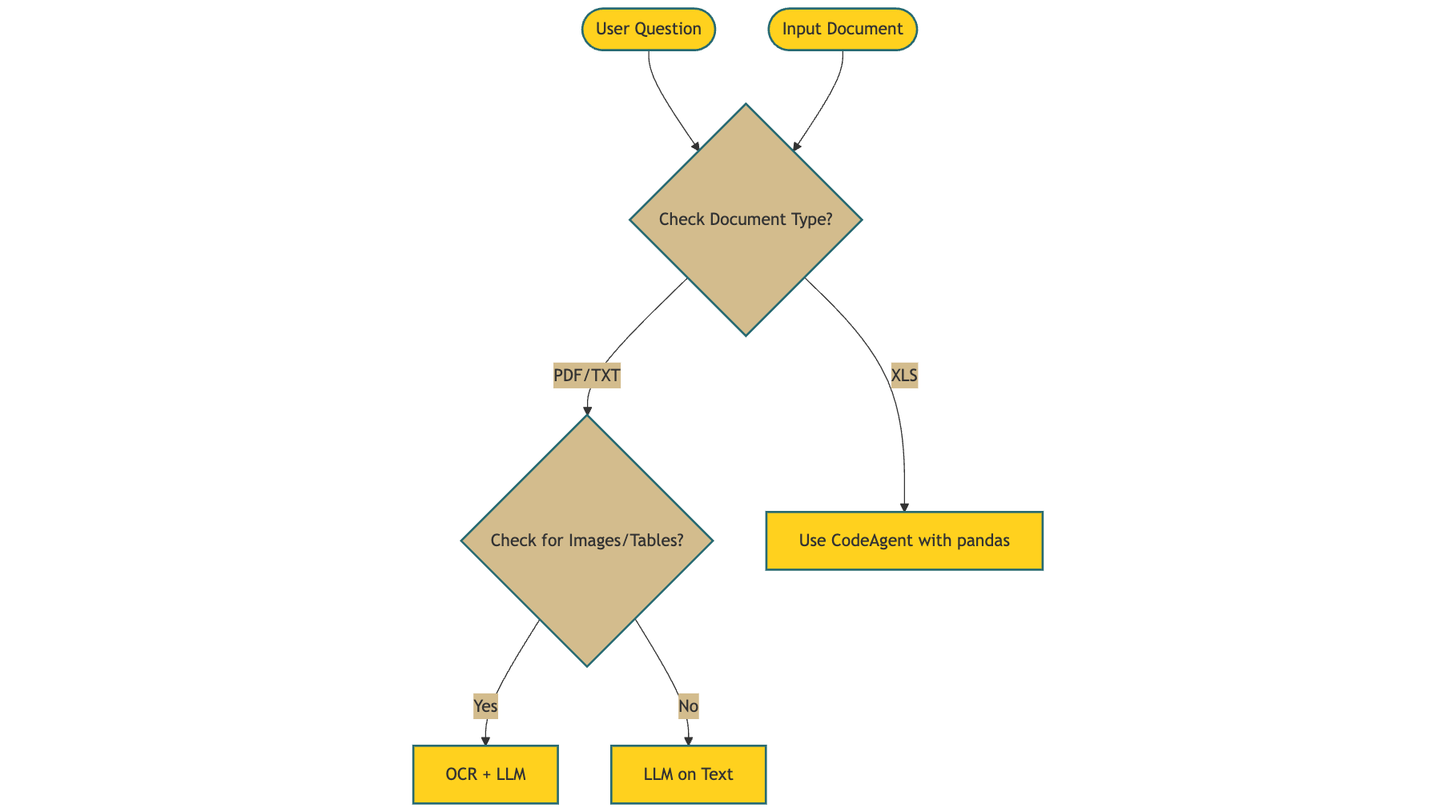
文档分析智能体的处理流程:
当需要人类设计行动流程并根据每个操作的输出决定下一步执行什么时,LangGraph 是最佳选择。
2. LangGraph 工作原理¶
LangGraph 使用有向图结构来定义应用程序的流程:
- 节点:表示独立的处理步骤(如调用LLM、使用工具或做出决策)
- 边:定义步骤之间可能的转换
- 状态:由用户定义和维护,在执行期间在节点间传递
与普通Python相比的优势
虽然可以用常规Python代码和if-else语句处理流程,但LangGraph提供了更多优势:
- 内置状态管理
- 工作流可视化
- 日志追踪(traces)
- 内置的人类介入机制
- 更优雅的抽象层
LangGraph 被认为是市场上最适合生产环境的智能体框架。
3. LangGraph 核心构建模块¶
1. 状态 (State)
状态是 LangGraph 中的核心概念,表示流经应用程序的所有信息。
from typing_extensions import TypedDict
class State(TypedDict):
graph_state: str
# 其他需要跟踪的信息...
状态是用户自定义的,需要仔细设计以包含决策过程所需的所有数据!
2. 节点 (Nodes)
节点是实现具体功能的 Python 函数,每个节点:
- 接收状态作为输入
- 执行特定操作
- 返回状态更新
def node_1(state):
print("---Node 1---")
return {"graph_state": state['graph_state'] + " I am"}
def node_2(state):
print("---Node 2---")
return {"graph_state": state['graph_state'] + " happy!"}
节点可以包含: - LLM 调用:生成文本或做出决策 - 工具调用:与外部系统交互 - 条件逻辑:决定后续步骤 - 人工干预:获取用户输入
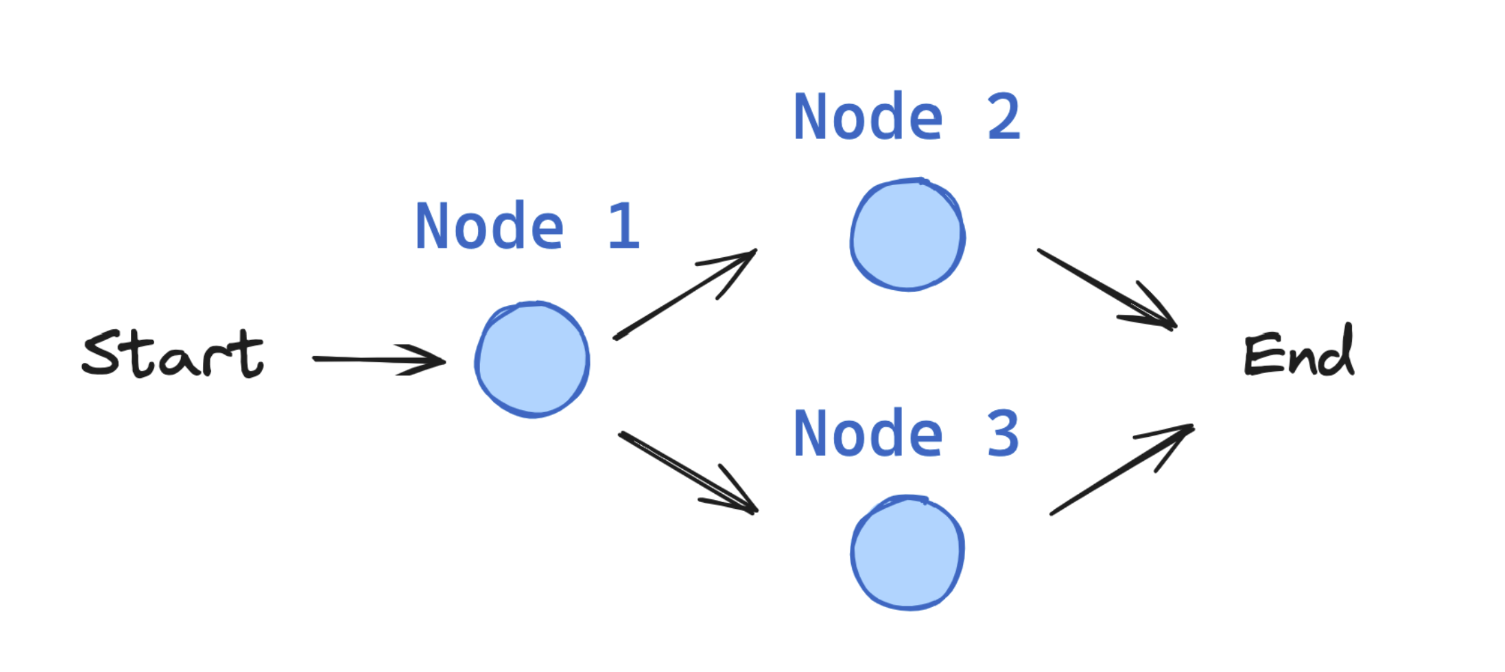
3. 边 (Edges)
边连接节点并定义图中的可能路径。边可以是:
- 直接边:始终从节点 A 到节点 B
- 条件边:根据当前状态选择下一个节点
def decide_mood(state) -> Literal["node_2", "node_3"]:
# 通常根据状态决定下一个节点
if random.random() < 0.5:
return "node_2" # 50% 时间
return "node_3" # 50% 时间
4. 状态图 (StateGraph)
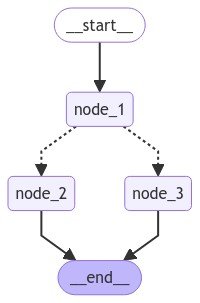
StateGraph 是包含整个 agent 工作流的容器:
from langgraph.graph import StateGraph, START, END
# 构建图表
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# 连接逻辑
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# 编译
graph = builder.compile()
4. 创建第一个 LangGraph 应用:邮件处理系统¶
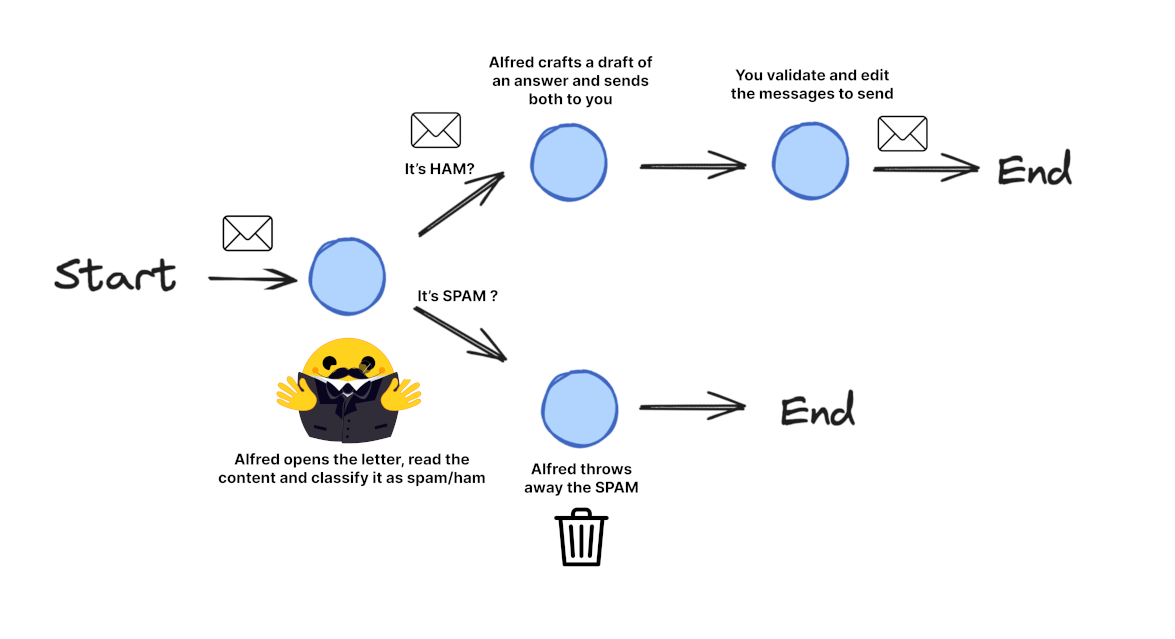
以下是构建一个邮件处理系统的步骤,该系统可以:
- 阅读传入的邮件
- 将邮件分类为垃圾邮件或合法邮件
- 为合法邮件起草初步响应
- 向用户发送通知
1. 定义状态
class EmailState(TypedDict):
# 正在处理的电子邮件
email: Dict[str, Any] # 包含主题、发件人、正文等
# 分析与决策
is_spam: Optional[bool]
# 响应生成
draft_response: Optional[str]
# 处理元数据
messages: List[Dict[str, Any]] # 跟踪与 LLM 的对话以进行分析
2. 定义节点
# 初始化 LLM
model = ChatOpenAI(temperature=0)
def read_email(state: EmailState):
"""读取并记录传入邮件"""
email = state["email"]
print(f"Processing email from {email['sender']} with subject: {email['subject']}")
return {}
def classify_email(state: EmailState):
"""使用 LLM 判断邮件是否为垃圾邮件"""
email = state["email"]
# LLM 提示准备
prompt = f"""
As Alfred the butler, analyze this email and determine if it is spam or legitimate.
Email:
From: {email['sender']}
Subject: {email['subject']}
Body: {email['body']}
First, determine if this email is spam. If it is spam, explain why.
If it is legitimate, categorize it (inquiry, complaint, thank you, etc.).
"""
# 调用 LLM
messages = [HumanMessage(content=prompt)]
response = model.invoke(messages)
# 解析响应
response_text = response.content.lower()
is_spam = "spam" in response_text and "not spam" not in response_text
# 更新状态并返回
return {
"is_spam": is_spam,
# 其他状态更新...
"messages": state.get("messages", []) + [
{"role": "user", "content": prompt},
{"role": "assistant", "content": response.content}
]
}
# 定义其他节点:handle_spam, draft_response, notify_user
3. 定义路由逻辑
def route_email(state: EmailState) -> str:
"""根据垃圾邮件分类确定下一步"""
if state["is_spam"]:
return "spam"
else:
return "legitimate"
4. 创建状态图并定义边
# 创建图
email_graph = StateGraph(EmailState)
# 添加节点
email_graph.add_node("read_email", read_email)
email_graph.add_node("classify_email", classify_email)
email_graph.add_node("handle_spam", handle_spam)
email_graph.add_node("draft_response", draft_response)
email_graph.add_node("notify_user", notify_user)
# 添加边 - 定义流程
email_graph.add_edge("read_email", "classify_email")
# 添加条件分支
email_graph.add_conditional_edges(
"classify_email",
route_email,
{"spam": "handle_spam", "legitimate": "draft_response"}
)
# 添加最后的边
email_graph.add_edge("handle_spam", END)
email_graph.add_edge("draft_response", "notify_user")
email_graph.add_edge("notify_user", END)
# 编译图
compiled_graph = email_graph.compile()
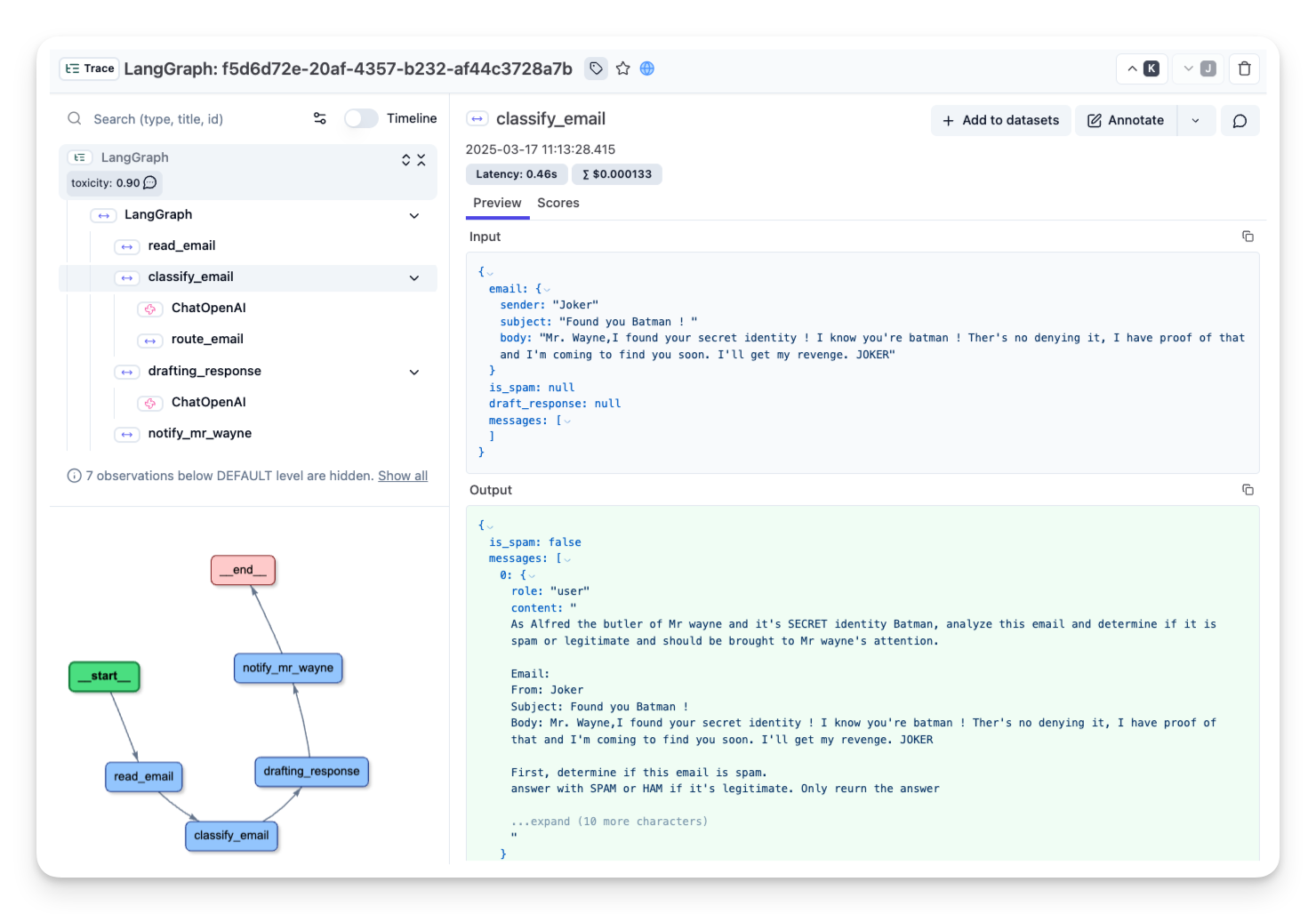
5. 应用流程图
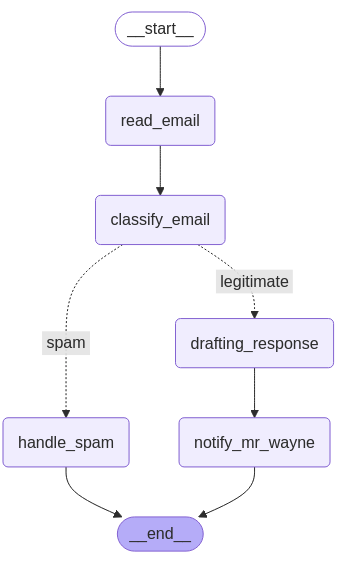
5. 文档分析智能体示例¶
1. 工作流程
文档分析智能体可以:
- 处理图像文档
- 使用视觉模型(VLM)提取文本
- 执行必要的计算
- 分析内容并提供摘要
- 执行与文档相关的特定指令
2. 状态定义
class AgentState(TypedDict):
# 提供的文件
input_file: Optional[str] # 包含文件路径(PDF/PNG)
# 消息历史
messages: Annotated[list[AnyMessage], add_messages]
3. 工具准备
# 初始化视觉LLM
vision_llm = ChatOpenAI(model="gpt-4o")
def extract_text(img_path: str) -> str:
"""从图像文件中提取文本"""
# 读取图像并转为base64编码
# 调用视觉模型提取文本
# 返回提取的文本
def divide(a: int, b: int) -> float:
"""计算工具示例"""
return a / b
# 为智能体配置工具
tools = [divide, extract_text]
llm = ChatOpenAI(model="gpt-4o")
llm_with_tools = llm.bind_tools(tools, parallel_tool_calls=False)
4. ReAct 模式
文档分析智能体遵循ReAct模式(推理-行动-观察):
- 推理:分析文档和请求内容
- 行动:通过调用合适的工具执行操作
- 观察:工具执行结果
- 重复:上述步骤直到完全满足需求
# 定义智能体节点
def assistant(state: AgentState):
# 系统消息
sys_msg = SystemMessage(content=f"You are an helpful butler...")
return {
"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])],
"input_file": state["input_file"]
}
# 构建图
builder = StateGraph(AgentState)
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# 定义边
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition, # 决定是否需要调用工具
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()
5. 使用场景示例
- 简单计算
用户: Divide 6790 by 5
AI Tool Call: divide(a=6790, b=5)
Tool Response: 1358.0
Alfred: The result of dividing 6790 by 5 is 1358.0.
- 文档分析
用户: 根据Wayne先生在提供的图像中的注释。我应该为晚餐菜单购买哪些物品?
AI Tool Call: extract_text(img_path="Batman_training_and_meals.png")
Tool Response: [包含训练计划和菜单详情的提取文本]
Alfred: 根据晚餐菜单,您应该购买以下物品:
1. 草饲本地西冷牛排
2. 有机菠菜
3. 皮克略辣椒
4. 土豆
5. 鱼油(2克)
确保牛排是草饲的,并且菠菜和辣椒是有机的,以获得最佳品质的餐点。
6. 开发文档分析智能体的关键原则¶
- 定义清晰的工具:用于特定文档相关任务
- 创建强大的状态跟踪器:保持工具调用之间的上下文
- 考虑错误处理机制:应对工具调用失败
- 保持上下文感知能力:通过 add_messages 操作符确保历史交互的连贯性
7. 监控和可观察性¶
使用 Langfuse 等工具跟踪和监控智能体:
from langfuse.callback import CallbackHandler
# 初始化 Langfuse
langfuse_handler = CallbackHandler()
# 使用 callbacks 调用 graph
result = compiled_graph.invoke(
input={...},
config={"callbacks": [langfuse_handler]}
)
这样可以实现对智能体行为的全面跟踪和监控,便于调试和改进。