UNIT1. INTRODUCTION TO AGENTS¶
理解智能体 (Understanding Agents)¶
1. 基本定义
智能体是一个系统,它利用人工智能模型与环境交互,以实现用户定义的目标。它结合推理、规划和动作执行(通常通过外部工具)来完成任务。
2. 工作流程
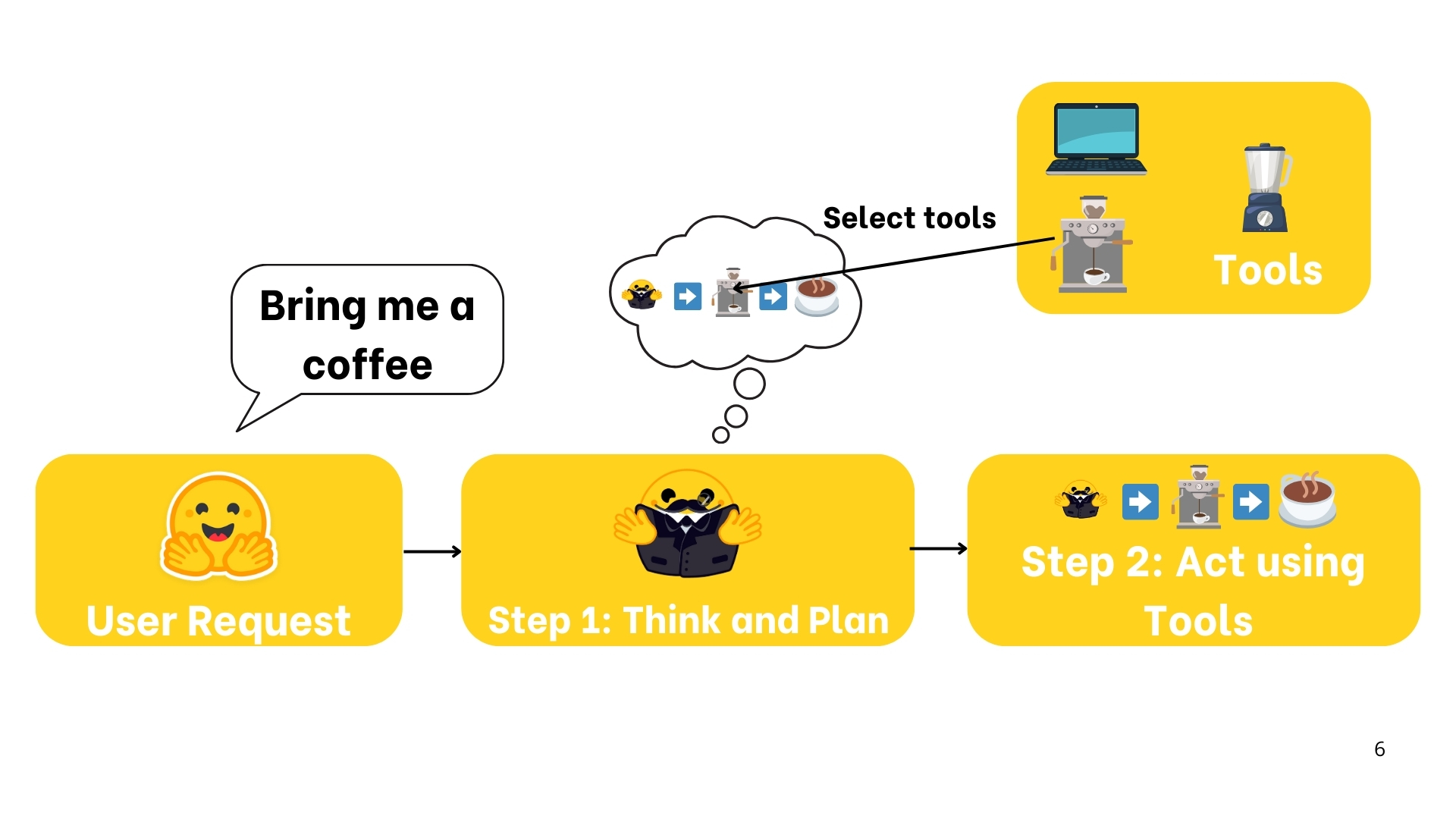
3. AI 模型在智能体中的应用
- 最常见的AI模型:LLM(大型语言模型),接收文本作为输入,输出文本
- 例如:OpenAI的GPT4、Meta的LLama、Google的Gemini
- 其他可能的模型:视觉语言模型(VLM)等
4. 智能体核心功能总结
智能体是一个系统,它使用人工智能模型(通常是大语言模型)作为其核心推理引擎,以实现以下功能:
LLM本身只能生成文本,需要通过工具拓展能力
- 理解自然语言:以有意义的方式解释和回应人类指令
- 推理与规划:分析信息、做出决策并制定解决问题的策略
- 与环境交互:收集信息、执行操作并观察这些操作的结果
大型语言模型 (LLMs) 在智能体中的角色¶
LLMs¶
1. 什么是大型语言模型?
大型语言模型(LLM) 是一种擅长理解和生成人类语言的人工智能模型,通过大量文本数据的训练,能够学习语言中的模式、结构和细微差别。它们通常基于Transformer架构构建,包含数十亿个参数。
2. Transformer架构类型
Transformer架构有三种主要类型,大多数LLMs都是基于解码器的模型:
Transformer架构
├── 编码器(Encoders)
│ ├── 功能:输出文本的密集表示(嵌入)
│ ├── 示例:Google的BERT
│ ├── 用例:文本分类、语义搜索、命名实体识别
│ └── 规模:数百万个参数
├── 解码器(Decoders)
│ ├── 功能:逐个生成新令牌以完成序列
│ ├── 示例:Meta的Llama
│ ├── 用例:文本生成、聊天机器人、代码生成
│ └── 规模:数十亿个参数
└── 序列到序列(编码器-解码器)
├── 功能:结合编码器和解码器
├── 示例:T5、BART
├── 用例:翻译、摘要、改写
└── 规模:数百万个参数
3. 主要LLM提供商
| 模型 | 提供商 |
|---|---|
| Deepseek-R1 | DeepSeek |
| GPT4 | OpenAI |
| Llama 3 | Meta (Facebook AI Research) |
| SmolLM2 | Hugging Face |
| Gemma | |
| Mistral | Mistral |
4. LLM的基本原理
- 目标:在给定一系列前一个令牌的情况下,预测下一个令牌
- 令牌:LLM处理信息的基本单位,可以理解为"子词单元"
- 特殊令牌:每个LLM都有特定的特殊令牌,用于标记序列开始/结束等
不同模型的特殊令牌示例:
| 模型 | 提供商 | EOS令牌 | 功能 |
|---|---|---|---|
| GPT4 | OpenAI | <\|endoftext\|> |
消息文本结束 |
| Llama 3 | Meta | <\|eot_id\|> |
序列结束 |
| Deepseek-R1 | DeepSeek | <\|end_of_sentence\|> |
消息文本结束 |
| SmolLM2 | Hugging Face | <\|im_end\|> |
指令或消息结束 |
| Gemma | <end_of_turn> |
对话轮次结束 |
5. LLM的词元预测过程
- 文本词元化:将输入文本转换为令牌
- 计算表示:捕获输入序列中每个令牌的意义和位置信息
- 生成分数:对词汇表中每个词元作为下一个词元的可能性进行排名
- 选择词元:使用不同解码策略(如贪婪解码、束搜索)选择下一个词元
6. 注意力机制
注意力机制是Transformer架构的关键,它能识别句子中最相关的词来预测下一个词元。
LLM的上下文长度指其能处理的最大词元数和最大注意力跨度。
7. LLM训练过程
- 预训练:在大型文本数据集上通过自监督学习,预测序列中的下一个词
- 微调:在初始预训练后,针对特定任务进行微调
8. LLM在智能体中的作用
LLM是AI智能体的"大脑",为理解和生成人类语言提供基础,能够解释用户指令、保持对话上下文、制定计划并决定使用哪些工具。
消息和特殊令牌¶
1. 消息系统基础
当用户与ChatGPT等系统交互时,表面上是在交换消息,但在后台:
- 所有消息都被连接并格式化成单一提示
- 模型每次都会完整读取全部内容,不会"记住"对话
2. 消息类型
系统消息(System Messages):
- 定义模型应如何表现的持久性指令
- 提供关于可用工具的信息
- 为模型提供行动格式化指令和思考过程分段指南
system_message = {
"role": "system",
"content": "You are a professional customer service agent. Always be polite, clear, and helpful."
}
用户和助手消息(User and Assistant Messages):
- 对话由人类(用户)和LLM(助手)之间的交替消息组成
- 通过保存对话历史维持上下文
conversation = [
{"role": "user", "content": "I need help with my order"},
{"role": "assistant", "content": "I'd be happy to help. Could you provide your order number?"},
{"role": "user", "content": "It's ORDER-123"},
]
3. 聊天模板(Chat Templates)
聊天模板是对话消息与LLM特定格式要求之间的桥梁,确保每个模型都能接收到正确格式化的提示。
基础模型vs指令模型:
- 基础模型:在原始文本数据上训练以预测下一个令牌
- 指令模型:专门微调以遵循指令并进行对话
聊天模板实现:
聊天模板使用Jinja2代码描述如何将ChatML消息列表转换为模型可理解的文本表示:
# SmolLM2-135M-Instruct聊天模板简化版
{% for message in messages %}
{% if loop.first and messages[0]['role'] != 'system' %}
<|im_start|>system
You are a helpful AI assistant named SmolLM, trained by Hugging Face
<|im_end|>
{% endif %}
<|im_start|>
{{ message['role'] }}
{{ message['content'] }}
<|im_end|>
{% endfor %}
4. 消息到提示的转换
使用模型标记器的chat_template来确保LLM正确接收格式化对话:
from transformers import AutoTokenizer
# 定义消息
messages = [
{"role": "system", "content": "You are an AI assistant with access to various tools."},
{"role": "user", "content": "Hi!"},
{"role": "assistant", "content": "Hi human, what can help you with?"},
]
# 加载标记器并应用聊天模板
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-1.7B-Instruct")
rendered_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
工具和行动 (Tools and Actions)¶

1. AI工具的定义
工具(Tools) 是赋予LLM的函数,用于实现明确的目标。优秀的工具应能补充LLM的核心能力。
常用工具示例如下:
| 工具类型 | 描述 |
|---|---|
| 网络搜索 | 允许智能体从互联网获取最新信息 |
| 图像生成 | 根据文本描述生成图像 |
| 信息检索 | 从外部源检索信息 |
| API接口 | 与外部API交互(GitHub、YouTube、Spotify等) |
合格工具的组成要素:
- 函数功能的文本描述
- 可调用对象(执行操作的实体)
- 带类型声明的参数
- (可选)带类型声明的输出
2. 工具的工作原理
LLM本身只能接收文本输入并生成文本输出,无法直接调用工具。真正的工作流程是:
- 通过系统提示教导LLM认识工具的存在
- 当需要时,LLM生成调用工具的文本(如代码形式)
- 智能体负责解析LLM输出、识别工具调用需求并执行
- 工具执行结果返回给LLM,由其生成最终用户响应
从用户视角看,仿佛LLM直接使用了工具,但实际执行者是应用代码(智能体)。
3. 如何为LLM提供工具
核心是通过系统提示向模型描述可用工具,需精准说明:
- 工具功能
- 预期输入格式
工具描述示例:
以计算器工具为例,Python实现如下:
对应的工具描述文本:
4. 自动化工具描述生成
可利用Python的自省特性从源代码自动构建工具描述,只需确保工具实现满足:
- 使用类型注解(Type Hints)
- 编写文档字符串(Docstrings)
- 采用合理的函数命名
装饰器实现:
@tool
def calculator(a: int, b: int) -> int:
"""Multiply two integers."""
return a * b
print(calculator.to_string())
# 输出: 工具名称:calculator,描述:将两个整数相乘。参数:a: int, b: int,输出:int
5. 通用工具类实现
以下是一个通用Tool类的实现,可用于创建和管理工具:
class Tool:
"""
A class representing a reusable piece of code (Tool).
Attributes:
name (str): Name of the tool.
description (str): A textual description of what the tool does.
func (callable): The function this tool wraps.
arguments (list): A list of argument.
outputs (str or list): The return type(s) of the wrapped function.
"""
def __init__(self,
name: str,
description: str,
func: callable,
arguments: list,
outputs: str):
self.name = name
self.description = description
self.func = func
self.arguments = arguments
self.outputs = outputs
def to_string(self) -> str:
"""
Return a string representation of the tool,
including its name, description, arguments, and outputs.
"""
args_str = ", ".join([f"{arg_name}: {arg_type}" for arg_name, arg_type in self.arguments])
return (f"Tool Name: {self.name},"
f" Description: {self.description},"
f" Arguments: {args_str},"
f" Outputs: {self.outputs}")
def __call__(self, *args, **kwargs):
"""
Invoke the underlying function (callable) with provided arguments.
"""
return self.func(*args, **kwargs)
工具装饰器的实现原理:
- 装饰器利用Python的
inspect模块自动提取函数信息:
def tool(func):
"""
A decorator that creates a Tool instance from the given function.
"""
# 获取函数签名
signature = inspect.signature(func)
# 提取输入参数的名称和类型
arguments = []
for param in signature.parameters.values():
annotation_name = (
param.annotation.__name__ if hasattr(param.annotation, '__name__')
else str(param.annotation)
)
arguments.append((param.name, annotation_name))
# 确定返回类型注解
return_annotation = signature.return_annotation
if return_annotation is inspect._empty:
outputs = "No return annotation"
else:
outputs = (
return_annotation.__name__ if hasattr(return_annotation, '__name__')
else str(return_annotation)
)
# 使用函数文档字符串作为描述
description = func.__doc__ or "No description provided."
# 函数名称作为工具名称
name = func.__name__
# 返回新的Tool实例
return Tool(
name=name,
description=description,
func=func,
arguments=arguments,
outputs=outputs
)
6. 工具的重要性
工具在增强AI智能体能力方面至关重要:
- 帮助智能体突破静态模型训练的局限
- 使智能体能处理实时任务并执行专业操作
- 提供访问外部数据和执行复杂计算的能力
智能体工作流程 (Agent Workflow)¶
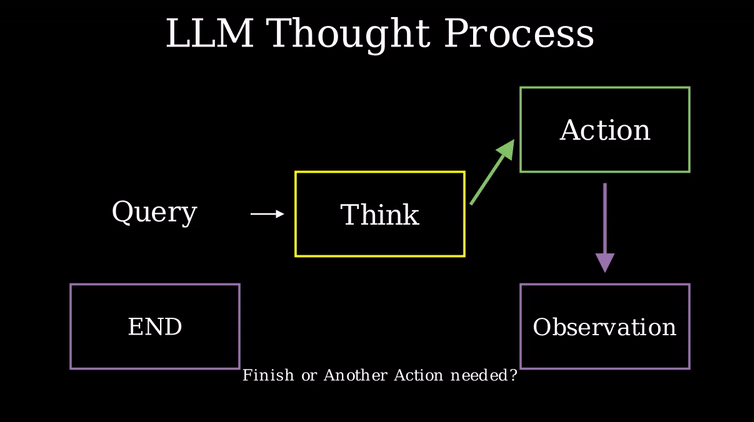
1. 思考-行动-观察循环
智能体在一个持续的循环中工作:思考(Thought) → 行动(Act) → 观察(Observe)。
这三个组件协同工作,形成智能体运行的核心机制:
┌─────────────┐
│ │
│ 思考 │◄─────────┐
│ (Thought) │ │
│ │ │
└──────┬──────┘ │
│ │
▼ │
┌─────────────┐ ┌─────────────┐
│ │ │ │
│ 行动 │ │ 观察 │
│ (Action) │────►(Observation)│
│ │ │ │
└─────────────┘ └─────────────┘
在许多智能体框架中,规则和指南直接嵌入到系统提示中,确保每个循环都遵循定义的逻辑。
2. 示例:阿尔弗雷德天气智能体
用户查询:"今天纽约的天气如何?"
循环展开过程:
-
思考(Thought):
-
行动(Action):
-
观察(Observation):
-
更新的思考:
-
最终行动:
3. 思维机制:内部推理与ReAct方法
思维(Thought)代表着智能体解决任务的内部推理与规划过程,利用LLM能力分析prompt中的信息。
常见思维模式:
| 思维类型 | 示例 |
|---|---|
| 规划(Planning) | "我需要将任务分解为三步:1)收集数据 2)分析趋势 3)生成报告" |
| 分析(Analysis) | "根据错误信息,问题似乎出在数据库连接参数" |
| 决策(Decision Making) | "考虑到用户的预算限制,应推荐中端选项" |
| 问题解决(Problem Solving) | "优化此代码需先进行性能分析定位瓶颈" |
| 记忆整合(Memory Integration) | "用户先前提到偏好Python,因此我将提供Python示例" |
| 自我反思(Self-Reflection) | "上次方法效果不佳,应尝试不同策略" |
| 目标设定(Goal Setting) | "完成此任务需先确定验收标准" |
| 优先级排序(Prioritization) | "在添加新功能前应先修复安全漏洞" |
ReAct方法:
ReAct是"推理"(Reasoning/Think)与"行动"(Acting/Act)的结合,一种简单的提示技术:
- 在让LLM解码前添加"Let's think step by step"(让我们逐步思考)的提示
- 引导模型将问题分解为子任务,而非直接输出最终解决方案
- 使模型能够更详细地考虑各个子步骤,通常产生更少错误

4. 行动:智能体与环境交互
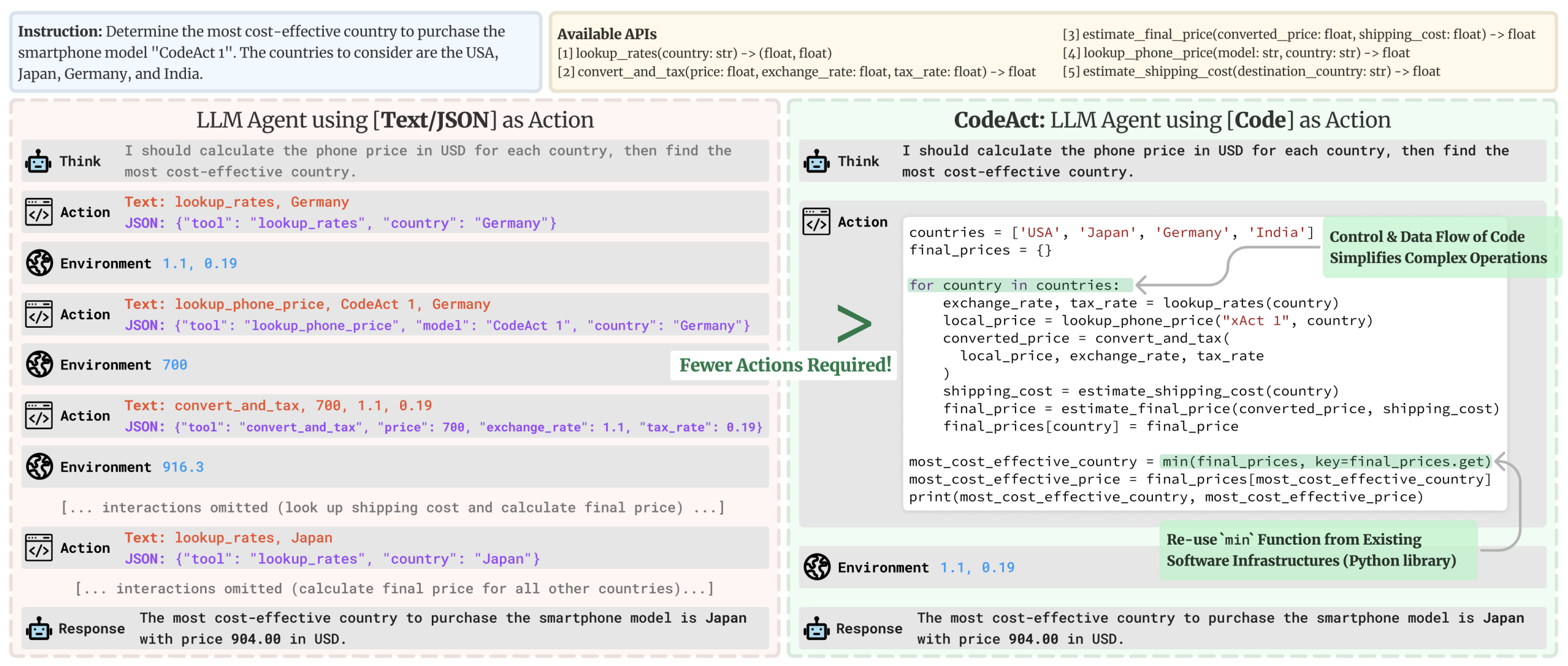
行动(Action)是AI智能体与环境交互的具体步骤。
智能体类型
| 智能体类型 | 描述 |
|---|---|
| JSON智能体 | 要执行的行动以JSON格式指定 |
| 代码智能体 | 智能体编写代码块,由外部解释执行 |
| 函数调用智能体 | JSON智能体的子类别,经过微调以为每个行动生成新消息 |
停止和解析方法
停止和解析方法(Stop and Parse Approach)确保智能体的输出具有结构性和可预测性:
- 以结构化格式生成:智能体以清晰、预定义的格式(JSON或代码)输出其预期行动
- 停止进一步生成:一旦行动完成,智能体停止生成额外的标记
- 解析输出:外部解析器读取格式化的行动,确定要调用哪个工具,并提取所需参数
代码智能体示例
# Code Agent Example: Retrieve Weather Information
def get_weather(city):
import requests
api_url = f"https://api.weather.com/v1/location/{city}?apiKey=YOUR_API_KEY"
response = requests.get(api_url)
if response.status_code == 200:
data = response.json()
return data.get("weather", "No weather information available")
else:
return "Error: Unable to fetch weather data."
# Execute the function and prepare the final answer
result = get_weather("New York")
final_answer = f"The current weather in New York is: {result}"
print(final_answer)
5. 观察:整合反馈以反思和调整
观察(Observation)是智能体感知其行动结果的方式,它们提供关键信息,为智能体的思考过程提供燃料并指导未来行动。
观察阶段的任务:
- 收集反馈:接收数据或确认行动是否成功
- 附加结果:将新信息整合到现有上下文中,有效更新记忆
- 调整策略:使用更新后的上下文来优化后续思考和行动
观察类型:
| 观察类型 | 示例 |
|---|---|
| 系统反馈 | 错误信息、成功通知、状态码 |
| 数据变更 | 数据库更新、文件系统修改、状态变更 |
| 环境数据 | 传感器读数、系统指标、资源使用情况 |
| 响应分析 | API响应、查询结果、计算输出 |
| 基于时间的事件 | 截止时间到达、定时任务完成 |
6. 简单智能体库实现
智能体库的核心是在系统提示中附加信息。以下是一个简单智能体的系统提示示例:
请尽可能准确地回答以下问题。你可以使用以下工具:
get_weather: 获取指定地点的当前天气
使用工具的方式是通过指定一个JSON blob。具体来说,这个JSON应该包含`action`键(工具名称)和`action_input`键(工具输入参数)。
"action"字段唯一允许的值是:
get_weather: 获取指定地点的当前天气,参数:{"location": {"type": "string"}}
使用示例:
{{
"action": "get_weather",
"action_input": {"location": "New York"}
}}
必须始终使用以下格式:
Question: 需要回答的输入问题
Thought: 你应该始终思考要采取的一个行动(每次只能执行一个行动)
Action: $JSON_BLOB (inside markdown cell)
Observation: 行动执行结果(这是唯一且完整的事实依据)
...(这个Thought/Action/Observation循环可根据需要重复多次,$JSON_BLOB必须使用markdown格式且每次仅执行一个行动)
最后必须以下列格式结束:
Thought: 我现在知道最终答案
Final Answer: 对原始问题的最终回答
创建简单智能体
- 设置无服务器API:
import os
from huggingface_hub import InferenceClient
# 设置Hugging Face令牌
os.environ["HF_TOKEN"] = "hf_xxxxxxxxxxxxxx"
client = InferenceClient("meta-llama/Llama-3.2-3B-Instruct")
- 创建天气函数:
# 模拟的天气函数
def get_weather(location):
return f"the weather in {location} is sunny with low temperatures. \n"
- 使用chat方法调用智能体:
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "What's the weather in London?"},
]
- 处理智能体响应并执行工具调用:
# 获取模型响应
output = client.text_generation(
prompt,
max_new_tokens=200,
stop=["Observation:"] # 在观察前停止
)
# 执行工具并附加结果
new_prompt = prompt + output + get_weather('London')
# 继续生成
final_output = client.text_generation(
new_prompt,
max_new_tokens=200,
)
使用 smolagents 构建智能体¶
参考 https://huggingface.co/spaces/scott9/First_agent_template