09~15¶
第9章 在一起更好还是分开更好¶
关键结论
拆分或合并模块的决定应基于复杂性。应选择能够实现以下结构:
- 最佳信息隐藏
- 最少依赖关系
- 最深接口
当做出设计决策时,关注点应该是如何最大程度地减少整体系统的复杂性,而不是遵循死板的规则。
1. 核心问题
软件设计中最基本的问题之一:给定两个功能,它们应该在同一位置一起实现,还是应该分开实现?这个问题适用于系统中的所有级别,包括函数、方法、类和服务。
2. 决策原则
在决定是合并还是分开时,目标是降低整个系统的复杂性并改善其模块化。将系统划分成更小的组件看似可以简化每个单独组件,但细分也会带来额外的复杂性:
- 组件数量增加导致更难追踪和查找
- 需要额外的代码来管理组件间关系
- 创造了分离,使开发人员更难同时查看组件
- 可能导致代码重复
3. 何时合并代码?
如果代码段紧密相关,将它们组合在一起通常是有益的。
以下是判断两段代码相关的几个指标:
| 相关性指标 | 描述 |
|---|---|
| 信息共享 | 两段代码依赖于相同的信息,比如特定文档格式的语法 |
| 一起使用 | 使用一段代码的人很可能同时使用另一段(需是双向关系) |
| 概念重叠 | 存在一个简单的更高级别概念可以包含这两段代码 |
| 理解依赖 | 不看其中一段代码就很难理解另一段 |
4. 核心设计准则
4.1 如果信息共享则合并在一起
当两个模块需要共享大量相同信息时,这通常表明它们应该合并。
例如HTTP服务器中,读取HTTP请求和解析HTTP请求的方法分离会导致两个方法都需要了解HTTP请求的格式:
// 在不同类中分离读取和解析HTTP请求
type RequestReader struct {}
func (r *RequestReader) ReadRequest(socket net.Conn) (string, error) {
// 读取请求文本到字符串
// 但为了知道何时结束,需要部分解析请求...
return requestText, nil
}
type RequestParser struct {}
func (p *RequestParser) ParseRequest(requestText string) (Request, error) {
// 解析之前读取的请求文本
// 再次分析相同的格式信息
return request, nil
}
4.2 如果可以简化接口则合并在一起
当两个或多个模块组合为一个模块时,可能会简化整体接口。例如Java I/O库中,如果FileInputStream和BufferedInputStream类被合并,并默认提供缓冲,大多数用户无需关心缓冲的存在。
4.3 消除重复时合并在一起
如果发现反复重复的代码模式,可以通过重构来消除重复。
// 处理不同类型的网络数据包,每种类型都有相似的错误处理
func ProcessPackets(packets []Packet) {
for _, p := range packets {
if p.Type == TYPE_A {
if len(p.Data) < minLenA {
LOG("Packet too short for type A: %v", p)
continue
}
// 处理A类型包
} else if p.Type == TYPE_B {
if len(p.Data) < minLenB {
LOG("Packet too short for type B: %v", p)
continue
}
// 处理B类型包
} else if p.Type == TYPE_C {
if len(p.Data) < minLenC {
LOG("Packet too short for type C: %v", p)
continue
}
// 处理C类型包
}
}
}
// 重构后的代码,错误处理只有一处
func ProcessPackets(packets []Packet) {
for _, p := range packets {
minLen := 0
switch p.Type {
case TYPE_A:
minLen = minLenA
case TYPE_B:
minLen = minLenB
case TYPE_C:
minLen = minLenC
default:
continue
}
if len(p.Data) < minLen {
LOG("Packet too short for type %v: %v", p.Type, p)
continue
}
// 处理不同类型的包...
}
}
4.4 分离通用代码和专用代码
如果一个模块包含可用于多种不同目的的机制,它应该只提供通用机制,而不包含专门针对特定用途的代码。
例子:撤销机制设计
// 文本类包含所有撤销功能,包括与文本无关的内容
type Text struct {
// 文本相关字段
undoList []UndoAction
}
func (t *Text) AddTextUndoAction(action TextUndoAction) {
// 添加文本相关撤销动作
}
func (t *Text) AddSelectionUndoAction(action SelectionUndoAction) {
// 添加选择相关的撤销动作(与文本无关!)
}
func (t *Text) AddCursorUndoAction(action CursorUndoAction) {
// 添加光标相关的撤销动作(与文本无关!)
}
func (t *Text) Undo() {
// 混合处理所有类型的撤销动作
}
// 通用撤销机制
type History struct {
actions []Action
current int
}
// 通用动作接口
type Action interface {
Redo()
Undo()
}
func (h *History) AddAction(action Action) {
// 添加任何实现Action接口的动作
}
func (h *History) Undo() {
// 通用撤销处理
}
// 文本类只实现自己的特定撤销动作
type Text struct {
// 文本相关字段
}
// 文本的特定撤销动作
type TextInsertAction struct {
text *Text
position int
content string
}
func (a *TextInsertAction) Undo() {
// 撤销文本插入
}
// 用户界面模块实现自己的特定撤销动作
type Selection struct {
// 选择相关字段
}
type SelectionAction struct {
selection *Selection
oldRange Range
newRange Range
}
func (a *SelectionAction) Undo() {
// 撤销选择变更
}
5. 方法的拆分与合并
关于方法的拆分,长度本身很少是一个充分的理由。开发者通常过度拆分方法。方法拆分应该遵循以下原则:
- 只有在能使整个系统更简单时才拆分方法
-
拆分方法有两种主要方式:
- 提取子任务:将独立子任务提取为辅助方法(推荐)
- 分割功能:将一个复杂方法拆分为两个公开的方法
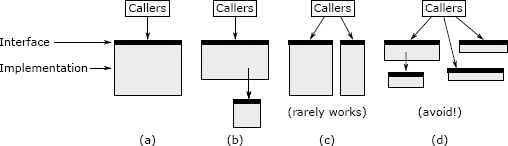
当拆分方法时需要警惕的信号:
- 联合方法:如果需要频繁在父子方法间切换才能理解功能,这表明拆分可能是错误的
第10章 通过定义规避错误¶
关键结论
特殊情况会使代码更难理解并增加bug的可能性。减少异常处理复杂性的四种主要技术是:
- 通过定义规避错误:重新定义API语义,消除错误条件
- 异常屏蔽:在低层处理异常,限制其影响范围
- 异常聚合:将多个特殊情况的处理聚合到一个通用处理程序
- 直接让程序崩溃:对于难以处理且罕见的错误,简单终止程序
这些技术可以显著降低系统的整体复杂性,使代码更易于理解和维护。
1. 异常处理的复杂性问题
异常处理是软件系统中最糟糕的复杂性来源之一。处理特殊情况的代码本质上比处理正常情况的代码更难编写,而开发人员经常在不考虑如何处理异常的情况下定义异常。
代码可能以几种不同方式遇到异常:
- 调用方提供错误的参数或配置信息
- 调用的方法无法完成请求的操作
- 分布式系统中的网络和服务问题
- 代码检测到内部错误或未准备处理的情况
异常处理之所以增加复杂性,主要有以下原因:
a. 处理代码本身复杂:异常处理需要决定是继续操作还是中止并上报
b. 引发更多异常:处理一个异常常常会引发新的异常情况
c. 语法冗长繁琐:异常处理的语法通常很啰嗦,破坏代码可读性
d. 难以测试:异常处理代码很少执行,难以确保其正常工作
2. 减少异常处理复杂性的四种技术
2.1 通过定义规避错误
核心思想:修改API的定义,使得特殊情况成为正常行为的一部分,从而消除异常。
示例:Tcl 的 unset 命令:
示例:Java 的 substring 方法
// 如果索引超出范围则抛出IndexOutOfBoundsException
func substring(s string, beginIndex, endIndex int) (string, error) {
if beginIndex < 0 || endIndex > len(s) || beginIndex > endIndex {
return "", errors.New("IndexOutOfBoundsException")
}
return s[beginIndex:endIndex], nil
}
// 使用时需要检查索引并处理异常
func extractText(s string, start, end int) string {
// 需要写5-10行代码来检查和调整索引
if start < 0 {
start = 0
}
if end > len(s) {
end = len(s)
}
if start > end {
start = end
}
result, err := substring(s, start, end)
if err != nil {
return ""
}
return result
}
// 重新定义:返回索引范围内的所有字符(如果有)
func substring(s string, beginIndex, endIndex int) string {
// 自动调整索引
if beginIndex < 0 {
beginIndex = 0
}
if endIndex > len(s) {
endIndex = len(s)
}
if beginIndex > endIndex {
beginIndex = endIndex
}
if beginIndex == endIndex {
return ""
}
return s[beginIndex:endIndex]
}
// 使用时简单直接
func extractText(s string, start, end int) string {
return substring(s, start, end) // 一行代码解决问题
}
示例:文件删除机制
Unix与Windows的文件删除机制对比:
| 特性 | Windows | Unix |
|---|---|---|
| 文件正在使用时 | 拒绝删除,返回错误 | 标记为删除,成功返回 |
| 用户体验 | 需搜索并关闭使用该文件的进程 | 可立即删除,无需其他操作 |
| 正在使用的文件 | 不允许创建同名新文件 | 可创建同名新文件 |
| 异常处理 | 需要处理"文件正在使用"的错误 | 无需处理特殊错误 |
2.2 异常屏蔽
核心思想:在低层检测并处理异常,使高层软件不需要感知异常。
示例:传输协议中的数据包丢失
TCP协议屏蔽了网络中数据包丢失的异常,在协议内部通过重发丢失的数据包来保证数据的可靠传输,应用层完全不需要处理这些异常。
示例:NFS网络文件系统
NFS文件系统在服务器暂时不可用时不会向应用程序报告错误,而是阻塞操作直到服务器恢复。虽然这会导致应用挂起,但比报告错误更好,因为:
- 应用程序通常无法合理处理文件访问失败的情况
- 如果报告错误,所有应用程序都需要添加重试逻辑
- 阻塞允许服务器恢复后自动继续操作,无需用户干预
2.3 异常聚合
核心思想:使用单个异常处理代码处理多种异常,而不是为每种异常编写单独的处理程序。
// Web服务器中分散处理缺失参数
func handleLogin(request *Request) Response {
username, err := request.getParameter("username")
if err != nil {
return createErrorResponse("参数'username'不存在")
}
password, err := request.getParameter("password")
if err != nil {
return createErrorResponse("参数'password'不存在")
}
// 处理登录逻辑...
}
func handleRegister(request *Request) Response {
username, err := request.getParameter("username")
if err != nil {
return createErrorResponse("参数'username'不存在")
}
email, err := request.getParameter("email")
if err != nil {
return createErrorResponse("参数'email'不存在")
}
// 处理注册逻辑...
}
// Web服务器中集中处理所有参数异常
func dispatchRequest(request *Request) Response {
var handler func(*Request) Response
// 根据URL选择处理函数
switch request.URL.Path {
case "/login":
handler = handleLogin
case "/register":
handler = handleRegister
default:
return createErrorResponse("未知路径")
}
// 聚合异常处理在顶层
defer func() {
if r := recover(); r != nil {
// 检查是否是NoSuchParameter类型的异常
if paramErr, ok := r.(NoSuchParameterError); ok {
return createErrorResponse(paramErr.Error())
}
// 重新抛出其他类型的异常
panic(r)
}
}()
return handler(request)
}
// 处理函数不再需要处理参数缺失的异常
func handleLogin(request *Request) Response {
username := request.getMustParameter("username")
password := request.getMustParameter("password")
// 处理登录逻辑...
}
func handleRegister(request *Request) Response {
username := request.getMustParameter("username")
email := request.getMustParameter("email")
// 处理注册逻辑...
}
// 辅助方法,如果参数不存在则通过panic传递异常
func (r *Request) getMustParameter(name string) string {
value, err := r.getParameter(name)
if err != nil {
panic(NoSuchParameterError{
Message: fmt.Sprintf("参数'%s'不存在", name),
})
}
return value
}
RAMCloud系统中的异常聚合
RAMCloud存储系统将小错误"提升"为大错误,使用相同的恢复机制处理多种错误:
- 当发现对象损坏时,不是单独恢复该对象,而是崩溃整个服务器
- 这样可以复用已有的服务器崩溃恢复机制,无需单独开发对象恢复机制
- 减少了需要编写和维护的代码量,提高了恢复机制的质量
2.4 直接让程序崩溃
核心思想:对于难以处理且罕见的错误,最简单的解决方案是打印诊断信息并中止应用程序。
适合直接崩溃的情况:
- 内存不足错误
- 罕见的I/O错误
- 网络套接字无法打开
- 检测到内部数据结构不一致
示例:内存分配失败
3. 通过设计规避特殊情况
特殊情况会导致代码中充斥着if语句,使代码难以理解并容易引入bug。应尽可能设计普通情况的处理方式,使其能够自动处理特殊情况。
示例:文本编辑器中的选择
type Selection struct {
start Position
end Position
// 没有exists字段,选择始终存在
// 当start == end时为空选择
}
func (s *Selection) copyText() string {
// 无需检查选择是否存在
// 如果start == end,自然返回空字符串
return textBetween(s.start, s.end)
}
func (s *Selection) deleteSelection() {
// 无需检查选择是否存在
// 如果start == end,删除操作自然不会有效果
newText := textBefore(s.start) + textAfter(s.end)
replaceText(newText)
}
4. 需要注意的边界
并非所有异常都应该被规避或屏蔽。如果异常信息对模块外部很重要,就必须将其暴露出来。
例如,在网络通信模块中,如果屏蔽了所有网络异常,应用程序将无法知道消息是否丢失或对端服务器是否故障,这会使构建健壮的应用程序变得不可能。
第11章 设计两次¶
关键结论
设计两次是一种实用的软件设计方法论,它承认设计是困难的,接受我们的第一想法通常不是最佳的。通过强制考虑多个方案,它不仅提高了设计质量,还培养了设计思维能力。这一原则适用于从单个类到整个系统的各个层次的设计决策。
对于软件设计者来说,应该把"设计多个方案并比较"视为常规做法,而不是特例。正如作者所说,这不是因为你不够聪明,而是因为问题本身确实很难,这正是软件设计有趣和有挑战性的地方。
1. 核心思想
设计两次的基本原则是:对于任何重要的设计决策,都应该考虑至少两种不同的方案,而不是仅实现首先想到的方案。这是因为设计软件非常困难,第一直觉很少能产生最佳设计。通过比较多个选项,可以得到更好的最终设计。
2. 设计两次的实践方法
2.1 步骤1:考虑多种设计方案
以GUI文本编辑器的文本管理类为例,可以考虑几种不同接口设计:
| 设计方案 | 描述 | 特点 |
|---|---|---|
| 面向行的接口 | 操作以整行文本为单位 | 在部分行和多行操作中需要拆分和合并行 |
| 面向字符的接口 | 以单个字符为单位插入删除 | 处理多字符操作需要循环调用 |
| 面向范围的接口 | 操作任意范围的字符,可跨行边界 | 能更好地匹配高级软件的需求 |
关键是选择彼此根本不同的方法,以便能学到更多。即使你确信只有一种合理方法,也要考虑第二种设计,无论它看起来多么不可行。
2.2 步骤2:评估各方案的优缺点
评估标准应包括:
- 高级软件使用的易用性(最重要)
- 接口的简洁性
- 通用性
- 实现效率
例如:面向字符的接口可能在处理多字符操作时效率低下,因为每个字符都需要单独的函数调用。
2.3 步骤3:选择或整合最佳设计
比较后,可能出现三种结果:
- 某一方案明显优于其他方案
- 可以整合多个方案的优点创造新设计
- 所有方案都不够理想,需要重新思考问题
如果所有方案都不够理想,应该仔细分析它们的共同问题。例如,如果只考虑了面向行和面向字符的方法,可能会发现它们都要求高级软件执行额外的文本操作,这是个危险信号——文本类应该处理所有文本操作。这种思考可能引导你设计出面向范围的API,从而解决前两种设计的问题。
3. 多层次应用设计两次原则
设计两次的原则可以应用于系统的多个层次:
// 面向行的接口
type LineTextEditor interface {
InsertLine(lineNum int, content string) error
DeleteLine(lineNum int) error
GetLine(lineNum int) (string, error)
// ...
}
// 面向字符的接口
type CharTextEditor interface {
InsertChar(position Position, char rune) error
DeleteChar(position Position) error
GetChar(position Position) (rune, error)
// ...
}
// 面向范围的接口
type RangeTextEditor interface {
Insert(position Position, text string) error
Delete(start, end Position) error
GetText(start, end Position) (string, error)
// ...
}
不同层次关注点不同:
- 接口设计:关注易用性、通用性
- 实现设计:关注简单性和性能
- 系统分解:关注模块间关系、责任分配
4. 设计两次的时间投入与回报
设计两次所需的额外时间投入通常很少,但回报丰厚:
| 模块规模 | 设计时间 | 实现时间 | 投资回报 |
|---|---|---|---|
| 小型类 | 1-2小时 | 数天或数周 | 显著更好的设计 |
| 大型模块 | 更多时间 | 更长时间 | 更高的收益 |
关键是:设计阶段的适度投资可以在实现阶段获得倍数回报。
5. 聪明人的设计陷阱
作者观察到,非常聪明的人有时难以接受设计两次的原则,原因可能是:
- 成长经历:聪明人可能习惯于第一个想法就足够好
- 自我认知:潜意识认为"聪明人应该第一次就做对"
- 错误的标准:将"一次成功"视为能力的衡量标准
然而,随着问题复杂度增加,每个人最终都会到达第一个想法不再足够好的境地。大型软件系统设计正是这种情况——没有人能第一次就做对。
6. 设计两次的双重收益
设计两次不仅能提高当前设计的质量,还能培养设计技能:
a. 设计质量提升:通过比较多个方案找到更优解决方案
b. 设计能力成长:了解什么因素使设计更好或更差
c. 判断力增强:逐渐能更快排除不良设计,聚焦优秀设计
第12章 为什么要写注释?有四个理由¶
关键结论
尽管存在多种借口,良好的注释对于软件开发至关重要。它们能捕获无法在代码中表示的关键设计信息,减轻认知负担,并支持软件抽象。反对写注释的常见借口都存在缺陷,而投入适当精力编写高质量文档会带来远超其成本的回报。
更重要的是,编写注释不应被视为事后的负担,而应成为设计过程的有机组成部分,能够积极改善软件设计质量。
1. 引言:注释的重要性
代码内文档在软件设计中扮演着至关重要的角色。注释不仅能帮助开发人员理解系统和高效工作,还在实现抽象方面发挥重要作用。没有注释,就无法有效隐藏复杂性。更值得注意的是,如果正确完成,编写注释的过程本身就能改善系统设计。
然而,这种观点并未得到普遍认同。相当多的生产代码中几乎没有注释,许多开发人员认为注释是浪费时间,或者虽然认识到注释的价值,但从不动手去写。即使在鼓励文档的团队中,注释也常被视为繁琐工作,而许多开发人员不知道如何编写,导致文档平庸。这种文档不足给软件开发带来巨大且不必要的拖累。
2. 开发人员避免写注释的四个借口
2.1 "好的代码是自解释的"
这个借口基于一个美好但不现实的神话。虽然通过良好的代码编写实践(如选择好的变量名)可以减少对注释的需求,但仍有大量设计信息无法在代码中表示,例如:
- 接口的非正式方面(方法的高级描述或结果含义)
- 设计决策的基本原理
- 调用特定方法的适用条件
如果用户必须阅读方法实现才能使用它,那么:
- 这将既费时又痛苦
- 这种做法会导致将代码分解成大量浅层方法
- 对于大型系统,通过阅读代码来学习行为是不切实际的
最重要的是,注释是抽象的基础。没有注释,方法的唯一抽象就是其声明,而声明缺少太多基本信息,无法单独提供有用的抽象。注释使我们能够捕获调用者所需的额外信息,同时隐藏实现细节。
2.2 "我没有时间写注释"
在时间压力下,将注释优先级降低是很诱人的。然而,如果允许文档被降低优先级,最终将没有文档。
反驳这一借口的是投资心态:
- 好的注释对软件可维护性有巨大影响,付出的努力很快会回本
- 编写注释实际上不需要太多时间。假设纯编码时间占开发时间的10%,即使花与编码同样多的时间写注释(这是保守估计),也只会增加约10%的开发时间
- 良好文档带来的好处会迅速抵消这一成本
更重要的是,与抽象相关的顶级文档(如类和方法文档)应当作为设计过程的一部分来写。编写这些文档本身就是一种设计工具,能够立即改善整体设计,立刻带来回报。
2.3 "注释会过时并产生误导"
虽然注释确实有时会过时,但这在实践中不应该是主要问题:
- 仅当代码发生较大变更时才需要对文档进行大的更改
- 通常代码变更本身比相应的文档更新要花费更多时间
- 可以通过良好的组织方式(如避免重复文档并保持文档靠近相应代码)降低维护成本
- 代码审查是检测和修复过时注释的有效机制
2.4 "我所看到的所有注释都是毫无价值的"
在四个借口中,这可能是最有道理的一个。每个软件开发者都曾见过无用的注释,大多数现有文档质量平平。
然而,这个问题是可解决的。一旦掌握方法,编写高质量文档并不困难。后续章节将提供编写和维护良好文档的框架。
3. 良好注释的益处
注释的核心目的是捕获设计者脑海中的、无法在代码中表示的信息。这些信息从低级细节(如应对硬件特性的特殊代码)到高级概念(如类的设计理念)不等。
良好注释的具体好处包括:
-
帮助后续开发者更快更准确地工作
- 没有文档,开发者必须重新推导或猜测原始设计知识
- 这将花费额外时间,并可能因误解原设计意图而引入bug
- 即使是原设计者回来修改代码,如果已过几周,也会忘记许多细节
-
减轻认知负荷
- 提供开发者需要的信息
- 帮助开发者忽略无关信息
- 避免需要阅读大量代码来重构设计者的思路
-
减少"未知的未知"
- 通过阐明系统结构,使开发者清楚了解与特定更改相关的信息和代码
-
阐明依赖关系并消除模糊性
- 好的文档可以清晰展示依赖关系
- 填补理解上的空白,消除模糊不清的地方
4. 文档与设计的关系
良好的注释不仅有助于理解和维护代码,还能改进设计本身:
- 编写接口文档迫使开发者从使用者角度思考
- 当注释难以编写时,通常表明设计有问题
- 在设计阶段编写文档可以在早期发现并解决问题
第13章 注释应该描述代码中不明显的内容¶
关键结论
注释的目标是确保系统的结构和行为对读者来说是显而易见的,使他们能够快速找到所需信息并自信地修改系统。尽管部分信息可在代码中表示,但仍有大量信息无法从代码中轻易推导,注释填补了这一空白。
写注释时,应从第一次阅读代码的人的角度考虑什么是"明显的"。如果代码审查中有人指出某些内容不明显,不要争辩,而是尝试理解他们发现的困惑点并加以澄清。
良好的注释能显著提升软件质量,使开发团队更高效地协作和维护代码。
1. 注释的基本原则
注释的核心原则是:注释应描述代码中不明显的内容。之所以需要编写注释,是因为编程语言的语句无法捕获开发人员在编写代码时脑海中的所有重要信息。注释记录这些信息,帮助后来的开发人员轻松理解和修改代码。
从代码中看不明显的内容可能包括:
- 索引范围的边界是包含还是排除
- 代码实现的原因或设计思路
- 开发人员遵循的规则(如调用顺序)
- 抽象的高级视图和用法
2. 选择注释约定
编写注释的第一步是确定注释约定,包括内容和格式。如果使用的语言有文档编译工具(如Java的Javadoc、C++的Doxygen等),应遵循这些工具的约定。这些约定确保了一致性,使注释更易于阅读和理解,也有助于确保实际编写注释。
3. 注释的主要类别
注释主要分为以下几类:
| 类别 | 描述 | 重要性 |
|---|---|---|
| 接口注释 | 位于模块(类、数据结构、函数等)声明前的注释块,描述模块的接口 | 最重要 |
| 数据结构成员注释 | 位于数据结构字段声明旁的注释 | 重要 |
| 实现注释 | 方法或函数代码内部的注释,描述代码内部工作原理 | 通常不是必需的 |
| 跨模块注释 | 描述跨模块边界依赖的注释 | 罕见但重要 |
最重要的是前两类注释。每个类都应有接口注释,每个类变量和方法都应有注释。只有在变量或方法声明极其明显时(如简单的getter和setter),才可略过注释。
4. 避免的错误:不要重复代码
最常见的注释问题是注释重复了代码——注释中的所有信息都可以轻松地从旁边的代码推断出来。
衡量注释是否有用的方法:从未见过代码的人能否仅通过查看旁边的代码写出这个注释?如果能,则注释没有使代码更易理解。
5. 有效注释的两种方式
5.1 低级注释增加精度
低级注释提供比代码更详细的信息,通过阐明代码的确切含义增加精度。这种注释最适合用于变量声明,如类实例变量、方法参数和返回值。
低级注释可补充的详细信息:
- 变量的单位是什么
- 边界条件是包含还是排除
- 空值的含义
- 资源释放或关闭的责任
- 变量的不变量或约束
为变量添加注释时,应关注名词而非动词——关注变量表示什么,而不是如何被操作。
5.2 高级注释增强直觉
高级注释提供比代码更抽象的信息,忽略细节并帮助读者理解代码的整体意图和结构。这种注释常用于方法内部和接口注释。
// 如果有一个使用与assignPos指向的PKHash相同会话的LOADING readRpc,
// 并且该readRPC中的最后一个PKHash小于当前分配的PKHash,
// 则我们将assigningPKHash放入该readRPC中。
int readActiveRpcId = RPC_ID_NOT_ASSIGNED;
for (int i = 0; i < NUM_READ_RPC; i++) {
if (session == readRpc[i].session &&
readRpc[i].status == LOADING &&
readRpc[i].maxPos < assignPos &&
readRpc[i].numHashes < MAX_PKHASHES_PERRPC) {
readActiveRpcId = i;
break;
}
}
编写高级注释时,应问自己:
- 这段代码试图做什么?
- 能解释这段代码的最简单描述是什么?
- 这段代码最重要的方面是什么?
6. 接口文档的编写
接口文档是用于定义抽象的关键注释。接口注释与实现注释应明确分离,以避免暴露实现细节。
6.1 类的接口注释
类的接口注释应提供该类提供的抽象的高级描述:
/**
* 此类实现HTTP协议的简单服务器端接口:
* 应用程序可以通过使用此类接收HTTP请求,处理请求并返回响应。
* 该类的每个实例对应于用于接收请求的特定套接字。
* 当前实现是单线程的,一次处理一个请求。
*/
public class Http {
...
}
6.2 方法的接口注释
方法的接口注释应包括:
- 描述调用者感知的方法行为的高级描述
- 对每个参数和返回值的精确描述
- 任何副作用的文档
- 可能抛出的任何异常的描述
- 调用前必须满足的任何前提条件
/**
* 从缓冲区复制一范围的字节到外部位置。
*
* \param offset
* 要复制的第一个字节在缓冲区内的索引。
* \param length
* 要复制的字节数。
* \param dest
* 复制字节的目标位置:必须有至少length字节的空间。
*
* \return
* 返回值是实际复制的字节数,如果请求的字节范围
* 超出缓冲区末尾,则可能少于length。如果请求的
* 范围与实际缓冲区没有重叠,则返回0。
*/
uint32_t Buffer::copy(uint32_t offset, uint32_t length, void* dest)
7. 实现注释:什么和为什么,而非如何
实现注释是方法内部用于帮助理解工作原理的注释。大多数短小简单的方法不需要实现注释。实现注释的主要目标是帮助读者理解代码在做什么,而不是如何做。
实现注释的常见用途:
-
描述代码块的高级目的:
-
描述循环的每次迭代中发生的事情:
-
解释代码的原因:尤其是对于不明显的技巧性代码或bug修复
对于长方法,为重要的局部变量添加注释也很有帮助,但大多数具有良好名称的局部变量不需要文档。
8. 跨模块设计决策的文档
跨模块设计决策的文档面临的主要挑战是找到一个放置位置,让开发人员能自然发现它。
处理方法:
- 如果有明显的中心位置,在那里添加注释(如枚举定义)
- 使用中央设计笔记文件(designNotes)记录跨模块问题
- 在相关代码处添加简短引用指向详细文档
// 示例:designNotes文件中的一个条目
> Zombies
-------
> A zombie is a server that is considered dead by the rest of the
> cluster; any data stored on the server has been recovered and will
> be managed by other servers. However, if a zombie is not actually
> dead (e.g., it was just disconnected from the other servers for a
> while) two forms of inconsistency can arise:
* A zombie server must not serve read requests...
* The zombie server must not accept write requests...
> RAMCloud uses two techniques to neutralize zombies. First,
...
// 在相关代码中的引用
// See "Zombies" in designNotes.
第14章 选择的名字¶
关键结论
精心选择的名称能使代码更加清晰明了。当开发者第一次遇到这个变量时,他们对其行为的第一反应通常是正确的。
选择好名字是一种投资思维:花一些额外时间选择好名字,将来处理代码会更容易,也不太容易引入错误。培养命名技巧也是一项投资,虽然初期可能令人沮丧且耗时,但随着经验积累会变得越来越容易,最终几乎不需要额外时间就能选择好名字。
命名最佳实践总结:
| 原则 | 说明 | 示例 |
|---|---|---|
| 创造清晰图像 | 名称应在读者心中创建被命名事物的清晰图像 | fileBlock比block更明确地表示文件中的块 |
| 保持精确 | 避免过于笼统或含糊的名称 | 用cursorVisible代替blinkStatus |
| 选择合适长度 | 名称应足够长以表达意思,但不应过长 | 循环中短变量名(如i)可接受,但复杂概念需要更详细名称 |
| 保持一致性 | 同一概念在整个代码库中使用相同名称 | 始终用fileBlock表示文件中的块位置 |
| 考虑使用范围 | 使用范围越大的变量,名称应越详细 | 局部短循环中可用i,全局变量需更具描述性 |
| 布尔变量用谓词 | 布尔变量名应表明true/false的含义 | isEmpty、hasElements、canRead |
| 区分相似概念 | 不同概念应使用不同名称,即使相似 | fileBlock/diskBlock而非都用block |
通过遵循这些原则,开发者可以创建更易于理解和维护的代码,降低引入错误的可能性。
1. 命名的重要性
为变量、方法和其他实体选择名称是软件设计中最被低估的方面之一。良好的名字本身就是一种文档形式,它们能使代码更易于理解,减少对额外文档的需求,并使错误更容易被发现。相反,不良的命名会增加代码复杂性,造成歧义和误解,进而导致错误。
名称选择是复杂度是递增的一个典型例子——为单个变量选择一个平庸名称可能影响不大,但软件系统中有成千上万的变量,为所有这些变量选择好名字将对整体复杂性和可管理性产生重大影响。
2. 名称错误导致的重大bug
有时即使是一个命名不当的变量也可能导致严重后果。作者在Sprite分布式操作系统项目中遇到的最具挑战性的bug就是由于名称选择不当造成的。
问题出在文件系统代码中,同一个名称block被用于两个不同的目的:
- 有时表示磁盘上的物理块号
- 有时表示文件中的逻辑块号
在代码某处,一个包含逻辑块号的block变量被错误地用在需要物理块号的场景中,导致磁盘上不相关的块被清零,造成数据损坏。虽然多人(包括作者)审查了这段错误代码,但都没有注意到问题,因为看到block时都本能地假设它持有正确类型的值。
如果使用不同的变量名,如fileBlock和diskBlock,这种错误很可能不会发生,因为程序员会知道不能在那种场景下使用fileBlock。
3. 名称的核心目标
选择名称时,目标是在读者心中创造一幅关于被命名事物本质的图像。好的名称能传达大量关于底层实体是什么(以及同样重要的,不是什么)的信息。名称是一种抽象形式,它提供了一种简化的方式来思考更复杂的底层实体。
测试名称质量的问题:如果某人孤立地看到这个名称,没有看到其声明、文档或使用该名称的代码,他们能多准确地猜出这个名称指的是什么?
4. 名称应该精确
好名称有两个特性:精确性和一致性。
最常见的命名问题是太笼统或含糊。例如:
"count"太笼统——计数什么?更精确的名称如getActiveIndexlets或numIndexlets能让读者无需查看文档就能猜测方法的功能。
其他不够精确的命名例子:
- 使用
x和y表示文件中字符位置,应改为charIndex和lineIndex - 使用
blinkStatus表示光标可见状态,应改为cursorVisible - 使用
VOTED_FOR_SENTINEL_VALUE表示未投票状态,应改为NOT_YET_VOTED - 在没有返回值的方法中使用
result变量名,应该用更具体名称如mergedLine或totalChars
精确命名的例外情况:
- 作为短循环的迭代变量,使用
i和j这样的通用名称是可以的 - 如果变量的使用范围很小,能一眼看完,通用名称也可接受
名称也可能过于具体,如用selection作为表示要删除的文本范围的参数名,而该方法可以处理任何文本范围(不仅限于用户界面中已选中的文本)。
如果很难为变量想出一个精确、直观且不太长的名字,这是一个危险信号,表明该变量可能没有明确的定义或目的。
5. 一致使用名称
好名称的第二个重要属性是一致性。对于程序中反复出现的常见概念,应选择一个名称并在各处一致使用。这能减轻认知负担,让读者在不同上下文中看到名称时可以复用已有知识。
一致性有三个要求:
- 始终将通用名称用于特定目的
- 除了特定目的外,不使用该通用名称
- 确保目的足够狭窄,使所有具有该名称的变量行为一致
当需要多个引用同类事物的变量时,使用通用名称加上区分前缀,如srcFileBlock和dstFileBlock。
循环是一致性命名的另一个例子:如果使用i和j作为循环变量,应始终在最外层循环使用i,在嵌套循环中使用j。
6. 短名称与长名称的争论
关于命名长度存在不同观点。Go语言的一些开发者主张使用非常简短的名称,认为"长名称会模糊代码功能"。例如:
作者认为第二版本并不比第一版更难读,而且count比n更清晰地表明了变量的用途。然而,如果在整个系统中一致地使用n表示计数(且只表示计数),那么这个短名称对开发者而言可能是清晰的。
Go文化鼓励在多个不同场景中使用相同的短名称(如ch可表示字符或通道),但这种做法可能像block的例子一样导致混淆和错误。
可读性应该由读者而非作者决定。如果短名称的代码容易理解,那很好;如果有人抱怨代码晦涩,就应考虑使用更长的名称。
一个通用规则是:名称声明与使用之间的距离越大,名称应该越长。
第15章 先写注释¶
关键结论
如果你从未尝试过先写注释的方法,作者建议你尝试一下:
- 坚持足够长的时间,直到适应这种方式
- 思考它如何影响:
- 注释的质量
- 设计的质量
- 你对软件开发的整体体验
通过将注释编写融入设计过程,你不仅能创造更好的文档,还能获得更深入的设计洞察,并可能发现软件开发的新乐趣。
注释优先的实践指南:
| 开发阶段 | 传统方法 | 注释优先方法 | 优势 |
|---|---|---|---|
| 设计初期 | 只关注代码结构 | 编写类接口注释和主要方法接口注释 | 迫使思考抽象和整体设计 |
| 实现前 | 直接开始编码 | 迭代接口注释,确定关键变量并注释 | 提前稳定抽象,减少后期变更 |
| 编码过程 | 专注编码,不写注释 | 实现代码的同时完善注释 | 注释质量更高,设计得到验证 |
| 测试阶段 | 发现设计问题,重构代码 | 问题往往在编写注释时已发现并解决 | 减少重构,提高效率 |
| 完成后 | 匆忙补写注释,质量低 | 代码完成时注释已完成 | 无需额外时间,文档质量高 |
通过这种方法,注释不再是事后的负担,而是成为设计过程中的积极工具,能够带来更清晰的思考和更优质的软件设计。
1. 注释的时机问题
许多开发人员将编写文档推迟到开发过程的最后阶段,在编码和单元测试完成之后才着手处理。然而,这是产生低质量文档的最可靠方法之一。注释编写的最佳时机是在开发过程的开始,与代码编写同步进行。将注释编写作为设计过程的一部分,不仅能产生更好的文档,还能创造更优质的设计,并使编写文档的过程变得更加愉快。
2. 推迟编写注释的危害
2.1 开发者推迟编写注释的常见理由
大多数开发者推迟编写注释的典型理由是"代码仍在变化"。他们认为如果过早编写文档,日后代码变更时还需重写文档,因此最好等到代码稳定后再处理。但作者怀疑还有另一个原因:许多开发者将文档视为苦差事,因此尽可能地推迟这项工作。
2.2 推迟注释的负面后果
推迟编写注释会带来几个严重的负面后果:
-
注释可能永远不会被写出来
- 一旦开始推迟,很容易继续拖延
- 等代码完全稳定时,任务已变得庞大而不吸引人
- 很难找到合适的时间专门用几天来补全缺失的注释
-
即使最终写了,质量也会很低
- 此时开发者在心理上已经"完成"了这部分工作
- 只想尽快完成注释任务,敷衍了事
- 离设计过程已经过去一段时间,记忆变得模糊
- 注释往往只是重复代码,遗漏重要的设计思想
3. "先写注释"的方法
作者推荐一种不同的方法:先写注释,边写代码边完善注释。具体步骤如下:
- 首先编写类的接口注释
- 为最重要的公共方法编写接口注释和签名,但方法体保持为空
- 迭代这些注释,直到基本结构感觉合适
- 然后编写重要的类实例变量的声明和注释
- 最后填写方法的实现,并根据需要添加实现注释
- 在编写方法体时,为新发现需要的方法和变量同步添加注释
这种方法的结果是:当代码完成时,注释也同时完成。不会有积压的未完成注释。
4. "先写注释"方法的三大优势
4.1 产生更好的注释
- 设计类时写注释,关键设计思想清晰在脑海中,容易记录
- 在编写方法体前先写接口注释,可以专注于抽象和接口而不被实现细节分散注意力
- 在编码和测试过程中会自然注意到并修复注释中的问题
- 注释质量会随着开发过程不断提升
4.2 改善系统设计
注释是一种强大的设计工具。这是"先写注释"方法最重要的好处:
- 注释是完全捕获抽象的唯一方式,而良好的抽象是优秀系统设计的基础
- 在设计初期编写描述抽象的注释,可以在实现代码前审查和调整
- 编写好的注释需要识别变量或代码的本质,提炼出最重要的方面
- 如果不在设计早期这样做,就只是在"拼凑代码"而非设计
注释作为复杂性的警示信号,注释可以作为"煤矿中的金丝雀",提前警示设计问题:
- 如果一个方法或变量需要很长的注释,这是一个危险信号,表明你可能没有找到好的抽象
- 好的类应该是"深"的:简单接口实现强大功能
- 判断接口复杂性的最佳方法是查看其注释:
- 如果接口注释简短清晰却提供了使用所需的全部信息,说明接口简单
- 如果无法用简短注释完整描述方法,说明接口复杂
- 通过比较接口注释和实现可以评估方法的"深度":
- 如果接口注释必须描述实现的所有主要特性,则方法较"浅"
- 同样适用于变量:如果一个变量需要长篇注释才能完整描述,可能是变量分解不当的信号
这种评估使你能够及早发现并修正设计问题,而不是等到代码完成后才意识到设计缺陷。
4.3 让注释编写变得有趣
编写注释的第三个好处是使这个过程更愉快:
- 类的早期设计阶段往往是编程中最有趣的部分之一
- 注释是记录和测试设计决策质量的方式
- 寻找能用最少词语清晰表达的设计是一种挑战
- 当注释越简单,说明设计越好,这成为一种成就感的来源
- 如果你进行战略性编程(主要目标是优秀设计而非仅仅编写能工作的代码),注释编写应当是有趣的
5. 早期编写注释的成本分析
许多人认为延迟编写注释可以避免代码演变时重写注释的成本,但这种说法经不起简单计算:
- 估计编写代码和注释(包括修改)占总开发时间的比例,通常不超过10%
- 即使代码中有一半是注释,编写注释可能只占总开发时间的5%左右
- 将注释推迟到最后只能节省这部分时间的一小部分,并不显著
而采用"先写注释"方法的优势是:
- 在开始编写代码前,抽象会更加稳定
- 这可能会节省编码时间
- 相比之下,如果先写代码,抽象可能会随编码过程变化,需要更多代码修订
综合考虑所有因素,先写注释可能在总体上更高效。