01~08¶
0. 前言¶
1. 软件设计的缺失讨论
-
过去80年软件开发更关注流程(如敏捷)、工具(如版本控制)和编程范式(如面向对象),但关于如何设计高质量软件的核心问题长期未被深入探讨
-
作者指出1971年David Parnas的模块分解论文仍是该领域重要参考,暗示软件设计方法论进展缓慢
2. 核心问题:问题分解
-
计算机科学最根本挑战是将复杂问题拆分为可独立解决的模块,但学术界鲜有系统化教学
-
当前教育更侧重编程语法(如循环语句)而非设计思维训练
3. 程序员能力差异的根源
-
优秀程序员与普通程序员的核心差异在于设计能力,而非天赋
-
作者通过斯坦福CS190课程实践"写作式教学法":通过迭代开发→代码评审→重构改进的模式,帮助学生实践设计原则
4. 本书的实践基础
-
内容提炼自作者25万行代码的实战经验,涵盖操作系统、工具链、脚本语言等领域
-
设计原则强调哲学层面(如"消除错误的存在"),需通过具体编码实践理解
5. 开放性态度
- 作者声明本书非终极答案,鼓励读者结合自身经验辩证吸收
第1章 介绍¶
关键结论
软件设计是持续对抗复杂性的过程,优秀设计应使系统复杂度增速低于功能需求增速。
开发者需像作家反复润色文稿一样,通过迭代重构逼近理想设计状态。
1. 软件复杂性的本质
核心命题:软件开发的最大障碍是认知复杂性。程序员受限于理解不断膨胀的系统复杂性,导致开发效率下降、错误率上升。
复杂性来源:
- 组件间隐式依赖
- 功能迭代导致的逻辑交织
- 多人协作带来的设计理念冲突
2. 对抗复杂性的两种策略
| 策略 | 具体方法 | 关键示例 |
|---|---|---|
| 消除复杂性 | 通过简化代码逻辑降低认知负荷 | 统一命名规范,消除冗余条件分支 |
| 封装复杂性 | 模块化设计实现关注点分离 | 类/服务隔离实现,隐藏内部实现细节 |
3. 软件开发模型对比
-
瀑布模型缺陷:
- 预设完整设计在复杂系统中不可行
- 后期修改成本指数级增长(如桥梁中途改结构)
-
增量开发优势:
- 允许持续重构(如敏捷开发)
- 每个迭代周期暴露设计缺陷
- 早期经验优化后续功能实现
4. 软件设计的持续性特征
-
设计即重构:初始设计必然存在缺陷,需通过:
- 代码审查(他人视角发现设计问题)
- 危险信号识别(如过度嵌套/重复模式)
- 定期投入10-20%时间进行设计优化
-
设计平衡观:
- 警惕过度设计(如"Taking it too far"章节)
- 类深度 vs 接口简洁的权衡
5. 实践建议
-
学习路径:
- 通过真实代码审查理解设计原则
- 建立个人"危险信号"清单(如过长嵌套/模糊命名)
-
技术普适性:
- 虽然示例使用Java/C++,原则适用于C函数/微服务等场景
- 核心思想:通过抽象层级控制认知负载
第2章 复杂性的本质¶
关键结论
- 复杂性定律:软件维护成本 = f(依赖性×模糊性)
- 设计者的使命:通过降低模块耦合度、提升信息可见性,使系统复杂度增速 << 功能需求增速
- 终极检验标准:新成员能否在无文档情况下,凭直觉正确修改系统核心功能?
(第3章将具体探讨如何在日常开发中实践"零容忍"原则对抗复杂性)
1. 复杂性的本质定义
- 核心定义:任何导致系统难以理解和修改的软件结构特征
- 关键视角:以开发者完成具体任务时的体验为衡量标准,而非系统规模
- 数学表达:系统总复杂度 = Σ(各模块复杂度 × 开发者投入该模块的时间占比)
- 黄金法则:若他人认为你的代码复杂,则它就是复杂的(开发者的主观感受具有决定性)
2. 复杂性三大症状
| 症状 | 表现特征 | 典型案例 |
|---|---|---|
| 变更放大 | 简单修改需要调整多处代码 | 早期网站每个页面硬编码背景色,修改需遍历所有文件(图2.1a → 2.1b的改进) |
| 认知负荷 | 完成任务需掌握大量隐式知识 | C语言函数要求调用者手动释放内存,开发者必须记住此规则否则引发内存泄漏 |
| 未知的未知 | 无法预知修改会对哪些模块产生影响 | 修改中心背景色变量后,未发现某些页面使用其衍生色(图2.1c的强调色未同步更新) |
危害排序:未知的未知 > 认知负荷 > 变更放大
设计目标:通过"显而易见性(Obviousness)"对抗复杂性(第18章具体方法)
3. 复杂性的根本成因
Ⅰ 依赖性(Dependencies)
- 定义:代码修改必须联动调整其他相关部分
- 典型场景:
- 显性依赖:函数参数变更导致所有调用点需修改
- 隐性依赖:多模块共享全局状态(如旧版网站背景色分散定义)
- 管理原则:
- 隔离高频修改点(如现代网站集中管理颜色变量)
- 通过编译器强制(如变量重命名触发编译错误)
Ⅱ 模糊性(Obscurity)
- 定义:关键信息未被清晰传达
- 表现形式:
- 命名不当:
time变量未说明是秒/毫秒 - 文档缺失:错误码对应含义未记录
- 隐性约定:消息表与状态声明无显式关联
- 命名不当:
- 根治方法:
- 自解释设计 > 补充文档(第13章详述)
- 保持一致性(如禁用多用途变量名)
4. 复杂性的递增特性
- 累积机制:每个看似无害的微小设计缺陷(如一个模糊命名)叠加产生指数级维护成本
- 反直觉现象:
- 单一依赖/模糊性问题危害不大
- 但千级规模代码需面对网状交叉影响
- 防御策略:
- 零容忍哲学:每个提交都力求简化设计(第3章展开)
- 持续重构:像偿还技术债务一样修复微小缺陷
第3章 工作代码是不够的¶
关键结论
好的设计需要持续投资,但它最终会带来回报,而且比想象中更快。关键是:
- 保持一致地应用战略方法
- 将投资视为今天要做的事,而非推迟到明天
- 每个工程师都持续进行小规模的设计改进
- 避免"滑坡效应"——一旦开始推迟设计改进,很容易变成永久性延迟
核心启示:虽然战术编程可能带来短期收益,但从长远来看,战略编程是构建可持续、高质量软件系统的唯一途径。
1. 战术编程 vs 战略编程
战术编程和战略编程是两种截然不同的软件开发思维方式,它们的区别在于:
| 战术编程 | 战略编程 |
|---|---|
| 关注当下任务的快速完成 | 关注系统的长期结构和质量 |
| 短视的、功能驱动的 | 投资思维、设计驱动的 |
| 渐进式增加复杂性 | 持续性改进系统设计 |
| 优先考虑短期速度 | 优先考虑长期可维护性 |
| 倾向于避免重构 | 主动进行设计改进和重构 |
2. 战术编程的问题
战术编程的核心问题是短视。当开发者只关注快速完成当前任务时,会导致:
- 复杂性逐渐累积,没有人愿意花时间清理
- 代码质量持续下降,系统逐渐变得难以维护
- 形成"补丁上加补丁"的恶性循环
- 长期来看,开发速度显著降低
在一些组织中,存在"战术龙卷风"式的开发者——他们能极快地开发功能,但留下的代码质量差,需要其他开发者花费大量时间清理。
3. 战略编程的本质
战略编程的核心理念是:能工作的代码是不够的。开发者需要:
- 将系统的长期结构作为首要考虑因素
- 愿意投入时间改进设计,即使短期内会放慢速度
- 采取主动投资(找到简单设计、预见未来变化)和被动投资(发现问题时修复)
- 建议投入总开发时间的10-20%用于设计投资
4. 投资回报曲线
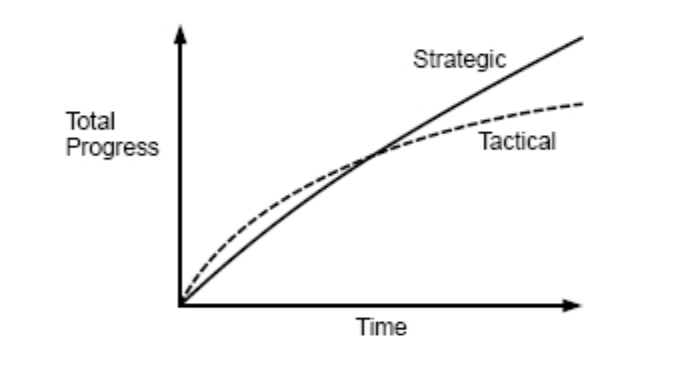
- 短期:战术方法看似更快,战略方法因投资设计而略慢
- 中期:战术方法积累的复杂性开始减缓开发速度,战略方法因良好设计开始加速
- 长期:战略方法明显更快,且投资变为"免费"——过去投资节省的时间足以覆盖未来投资
5. 创业公司的挑战与选择
创业公司面临更大的交付压力,但仍有两种截然不同的路径:
-
Facebook模式:"快速行动并打破常规"的战术方法 - 短期交付速度较快 - 代码库逐渐变得混乱难以维护 - 最终不得不改变方向:"以坚实的基础架构快速移动"
-
Google/VMware模式:战略性方法 - 注重高质量代码和良好设计 - 构建可靠的复杂系统 - 吸引顶尖技术人才的强大技术文化
第4章 模块应该是深的¶
关键结论
通过分离接口和实现,我们可以将实现的复杂性从系统的其余部分隐藏起来。设计类和模块的关键是使它们深入,为常见用例提供简单接口,同时提供重要功能。这最大限度地隐藏了复杂性。
核心思想:模块设计应该追求"深度"——用简单接口暴露强大功能,而非"宽度"——大量功能简单但接口复杂的浅层模块。
1. 模块化设计的本质
模块化设计是管理软件复杂性的关键技术,它允许开发人员在任何时刻只需面对整体复杂性的一小部分。在软件系统中,模块可以是类、子系统或服务等多种形式。
理想的模块化:每个模块完全独立,开发者可以在不了解其他模块的情况下工作。但这个理想无法完全实现,因为模块之间必须协同工作,这就产生了依赖关系。
模块化设计的目标:最小化模块之间的依赖性。
2. 模块的接口与实现
每个模块由两个关键部分组成:
| 接口 | 实现 |
|---|---|
| 其他模块开发者需要了解的内容 | 实现接口承诺的代码 |
| 描述"做什么",而非"怎么做" | 实现具体功能的内部细节 |
| 包括形式化元素(函数签名)和非形式化元素(行为、约束) | 对模块用户隐藏 |
良好接口的价值:它准确指示开发人员使用模块所需了解的内容,帮助消除"未知的未知"问题。
3. 抽象的概念
抽象是实体的简化视图,省略了不重要的细节。在模块化编程中,每个模块通过其接口提供抽象。
抽象可能出现的两类错误:
- 包含了不重要的细节:使抽象比必要的更复杂,增加认知负担
- 省略了重要的细节:导致模糊性,用户无法正确使用抽象
设计抽象的关键是识别什么是重要的,并寻找能将重要信息量最小化的设计。
4. 深度模块与浅层模块
4.1. 深度模块
深度模块提供强大功能但拥有简单接口,它们是好的抽象,因为只有很小一部分内部复杂性对用户可见。
深度模块可以用矩形来可视化:
- 矩形面积 = 模块实现的功能
- 顶部边缘长度 = 接口复杂性
- 最好的模块是"深的"矩形:面积大但顶边短
深度模块的优点:
- 最小化模块给系统其它部分带来的复杂性
- 如果修改不改变接口,则不会影响其他模块
深度模块的例子:
- Unix文件I/O:仅有5个基本系统调用(open, read, write, lseek, close),但实现了数十万行代码处理的复杂功能
- 垃圾收集器:几乎没有接口,在后台工作,但隐藏了复杂的内存回收机制
4.2 浅层模块
浅层模块的接口相对于其提供的功能而言过于复杂。
浅层模块的问题:
- 学习和使用接口的成本抵消了它提供的收益
- 没有显著帮助管理复杂性
极端例子:只有一行代码的方法addNullValueForAttribute,它增加了接口复杂性但没有提供任何抽象价值。
5. Classitis
当前编程中常见的误区是"类应该小"。这种思维导致了 Classitis:错误地认为"类是好的,所以类越多越好"。
Classitis 的问题:
- 小类单独可能简单,但增加了系统总体复杂性
- 需要大量小类,每个都有自己的接口
- 接口累积创造了系统级的巨大复杂性
- 导致冗长的编程风格
示例对比:
- Java I/O:打开一个文件读取序列化对象需要创建三个不同对象(FileInputStream, BufferedInputStream, ObjectInputStream)
- Unix I/O:设计者使常见情况简单,默认提供顺序I/O,而随机访问作为可选功能
6. 关键设计原则
接口设计的重要原则:应该设计接口以使常见情况尽可能简单。例如,若大多数用户需要缓冲,则应默认提供缓冲。
如果接口有许多功能,但大多数开发者只需了解其中几个,那么接口的有效复杂性就是常用功能的复杂性。
第5章 信息隐藏(和泄漏)¶
关键结论
信息隐藏与深层模块紧密相关: - 隐藏大量信息的模块通常功能丰富但接口简单,因此更深入 - 不隐藏信息的模块要么功能有限,要么接口复杂,通常是浅层的
系统分解的最佳方法是: - 避免受运行时操作顺序影响(时间分解) - 思考应用程序任务所需的不同知识 - 设计每个模块来封装这些知识中的一个或几个 - 这将产生干净、简单且深入的模块设计
核心思想:好的模块设计应该围绕知识封装而非时间顺序,通过隐藏实现细节来降低系统整体复杂性。
1. 信息隐藏的本质
信息隐藏是实现深层模块的最重要技术,由 David Parnas 首次提出。其核心思想是:每个模块应封装代表设计决策的知识,这些知识嵌入在模块实现中但不出现在接口中。
模块中隐藏的信息通常包括:
- 实现特定机制的数据结构和算法
- 较低级别的技术细节
- 较高级别的抽象概念和假设
2. 信息隐藏的双重价值
信息隐藏通过两种方式降低复杂性:
| 价值 | 描述 |
|---|---|
| 简化接口 | 提供更简单、更抽象的功能视图,隐藏细节,减少使用模块的开发人员的认知负担 |
| 促进系统演化 | 由于封装了知识,对相关设计决策的更改只会影响单个模块,而不会波及整个系统 |
3. 信息泄漏与其危害
信息泄漏是信息隐藏的反面,当一个设计决策反映在多个模块中时发生。这创建了模块间依赖关系:对该设计决策的任何更改都需要修改所有涉及模块。
信息可以通过两种方式泄漏:
- 通过接口泄漏:设计信息直接出现在接口中
- 后门泄漏:即使不在接口中,多个模块都依赖同一知识(如文件格式)
信息泄漏是软件设计中最重要的危险信号之一。应当培养对信息泄漏的高度敏感性,发现后应考虑重组类结构。
4. 时间分解:信息泄漏的常见原因
时间分解是一种设计风格,系统结构对应于操作将发生的时间顺序。这常导致信息泄漏,因为:
- 相同知识可能在不同时间点使用
- 将相关功能分散到多个类中
🚩 关键原则:在设计模块时,应关注执行每个任务所需的知识,而非任务发生的顺序。
5. 实例分析:HTTP服务器
5.1 问题1:太多浅层类
一些学生团队犯的错误是将HTTP请求处理分成两个类:一个读取请求,一个解析请求。这是时间分解的例子,导致了信息泄漏,因为:
- 读取HTTP请求需要解析大部分消息
- 两个类都需要了解HTTP请求的结构
- 解析代码在两个类中重复
解决方案:将相关功能合并到一个类中,提供更好的信息隐藏和更简单的接口。
5.2 改进信息隐藏的一般策略:适当增大类的规模
- 将相关功能集中到一起
- 提高接口级别(用一个高级方法替代多个低级方法)
- 结果:接口更简单,类更深入
5.3 问题2:HTTP参数处理
大多数学生项目在参数处理方面有两个好的设计决策:
- 隐藏参数来源(请求行vs请求体)的区别
- 隐藏URL编码的知识(自动解码)
但他们使用了太浅的接口:
这种设计的问题:
- 暴露内部表示
- 任何实现变更都会影响接口
- 增加调用者工作量
- 调用者可能无意修改内部状态
更好的接口设计:
这种设计:
- 隐藏内部实现
- 提供类型转换功能
- 简化调用
5.4 问题3:HTTP响应中的默认值
一些团队要求调用者显式指定HTTP响应的版本和时间,而这些信息通常可以自动从请求推断或系统获取。
改进原则:
- 接口应设计为使常见情况尽可能简单
- 默认值是部分信息隐藏的例子:通常情况下用户不需要知道这些细节
- 类应当"自动做正确的事",无需显式要求
6. 类内部的信息隐藏
信息隐藏也适用于类内部:
- 设计私有方法来封装和隐藏信息
- 尽量减少实例变量的使用范围
- 降低类内部的依赖关系和复杂性
7. 信息隐藏的界限
信息隐藏并非放之四海而皆准:如果模块外部需要某信息,就不应隐藏它。
作为设计者,目标应该是:
- 尽量减少模块外部需要的信息量
- 优先考虑自动调整而非暴露配置参数
- 正确识别哪些信息确实需要公开
第6章 通用模块更深入¶
关键结论
通用接口比专用接口具有明显优势:
- 更简单,方法更少但更深入
- 提供更清晰的类间分离
- 减少类间信息泄漏
- 适度通用化是降低整体系统复杂性的最佳方法之一
通用方法并非万能,但在设计时应尽量使模块"有点通用",在当前需求与未来扩展之间找到平衡点。
1. 核心理念
通用模块方法在软件设计中比专用模块方法更优越,能创建更简单、更深入的接口,实现更清晰的类间分离,并降低整体系统复杂性。
2. 通用与专用方法对比
| 通用方法 | 专用方法 |
|---|---|
| ✅ 更简单、更深入的接口 | ❌ 大量浅层方法 |
| ✅ 更清晰的模块间分离 | ❌ 模块间信息泄漏 |
| ✅ 降低认知负担 | ❌ 提高认知负担 |
| ✅ 更好的信息隐藏 | ❌ 造成虚假抽象 |
| ✅ 潜在的可重用性 | ❌ 难以用于其他场景 |
3. 关键原则:适度通用
作者提出"somewhat general-purpose"(适度通用)的概念:
- 模块的功能应反映当前需求
- 但接口不应被当前需求限制,而应足够通用以支持多种用途
- 接口应便于满足当前需求,但不应与特定需求紧密耦合
- 不要过度通用化而难以满足当前需求
4. 案例分析:文本编辑器
通过文本编辑器的设计案例对比了两种方法:
专用方法(不推荐):
void backspace(Cursor cursor);
void delete(Cursor cursor);
void deleteSelection(Selection selection);
通用方法(推荐):
void insert(Position position, String newText);
void delete(Position start, Position end);
Position changePosition(Position position, int numChars);
通用方法的优势:
- 操作基于基本文本概念,而非特定UI功能
- 使用通用类型(如
Position代替Cursor) - 减少了方法数量但保持了完整功能
- 提供了更清晰的类间分离
- 使高层实现(如退格和删除操作)更加明确
5. 判断好设计的问题
设计通用接口时可以自问的问题:
a. 什么是满足当前需求的最简单接口?
- 减少方法数量但保持功能完整性
- 简化不应导致参数过度复杂化
b. 这个方法会在多少情况下使用?
- 单一用途方法可能过于特殊化
- 尝试用通用方法替换多个专用方法
c. 这个API对当前需求易用吗?
- 过度简化可能导致使用复杂
- 应提供适当级别的抽象(如文本类支持字符范围操作)
第7章 不同的层,不同的抽象¶
关键结论
每增加一个设计元素(接口、参数、函数、类等)都会增加系统复杂性。要使元素对复杂性有净收益,它必须消除在没有该设计元素情况下存在的复杂性。
"不同层,不同抽象"原则的本质是:如果不同层使用相同抽象(如透传方法、装饰器或透传参数),这些层很可能没有提供足够的价值来补偿它们带来的额外复杂性。
1. 核心概念
软件系统由多个层组成,其中较高层使用较低层提供的功能。在设计良好的系统中,每一层都应提供与其上下层不同的抽象。当一个操作通过方法调用在层之间移动时,抽象应随每次方法调用而改变。
2. 问题识别:相似抽象的危害
当系统中相邻层具有相似抽象时,这表明类分解可能存在问题。这种情况通常表现为:
| 问题类型 | 定义 | 危害 | 解决思路 |
|---|---|---|---|
| 透传方法 (Pass-through Methods) |
一个方法除了将参数传递给另一个具有相同API的方法外,几乎不执行任何操作 | • 使类变浅:增加接口复杂性但不增加功能 • 创建类间依赖:一个类的签名更改导致另一类需同步修改 • 表明类间责任划分混乱或重叠 |
• 直接暴露底层类 • 重新分配类间功能 • 合并职责相关的类 |
| 透传变量 (Pass-through Variables) |
通过长方法链向下传递但在中间方法中不使用的变量 | • 强制中间方法感知其存在 • 增加系统整体复杂性 • 新增需求时需大规模修改中间层接口 |
• 利用共享对象 • 使用全局变量 • 引入上下文对象(推荐) |
3. 解决方案
3.1 处理透传方法
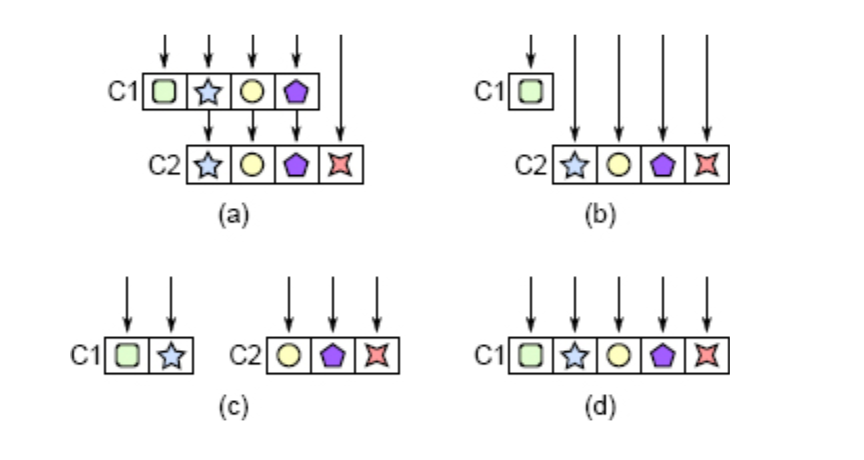 )
)
可采用以下几种方式消除透传方法:
a. 直接暴露底层类:让高层类的调用者直接调用低层类;
b. 重新分配功能:在类之间重新分配职责,避免类间调用;
c. 合并类:如果职责无法清晰分离,将相关类合并;
// TextArea 实现文本编辑的核心功能
type TextArea struct {
content string
cursor int
}
func (t *TextArea) GetCursorOffset() int {
return t.cursor
}
func (t *TextArea) InsertString(text string, offset int) {
// 实际的插入实现
if offset <= len(t.content) {
t.content = t.content[:offset] + text + t.content[offset:]
}
}
// TextDocument 只是透传调用到 TextArea
type TextDocument struct {
textArea *TextArea
}
// 透传方法 - 只是简单地将调用传给 TextArea
func (d *TextDocument) GetCursorOffset() int {
return d.textArea.GetCursorOffset()
}
// 透传方法 - 没有添加任何额外价值
func (d *TextDocument) InsertString(text string, offset int) {
d.textArea.InsertString(text, offset)
}
// 客户端代码
func main() {
textArea := &TextArea{}
doc := &TextDocument{textArea: textArea}
// 客户端必须知道 TextDocument,而它只是透传
doc.InsertString("Hello", 0)
pos := doc.GetCursorOffset()
}
// TextArea 处理基本操作
type TextArea struct {
content string
cursor int
}
func (t *TextArea) GetCursorOffset() int {
return t.cursor
}
func (t *TextArea) InsertCharacters(text string, offset int) {
if offset <= len(t.content) {
t.content = t.content[:offset] + text + t.content[offset:]
}
}
// TextDocument 提供更高级的文档操作
type TextDocument struct {
textArea *TextArea
history []string // 增加了撤销功能
}
// 不再是透传方法,增加了撤销历史记录功能
func (d *TextDocument) InsertString(text string, offset int) {
// 保存当前状态用于撤销
d.history = append(d.history, d.textArea.content)
// 调用底层功能,但增加了价值
d.textArea.InsertCharacters(text, offset)
}
// 新增高级功能
func (d *TextDocument) Undo() bool {
if len(d.history) > 0 {
lastIdx := len(d.history) - 1
d.textArea.content = d.history[lastIdx]
d.history = d.history[:lastIdx]
return true
}
return false
}
// 合并 TextArea 和 TextDocument 的功能
type TextEditor struct {
content string
cursor int
history []string
}
func (e *TextEditor) GetCursorOffset() int {
return e.cursor
}
func (e *TextEditor) InsertString(text string, offset int) {
// 保存历史用于撤销
e.history = append(e.history, e.content)
// 执行插入
if offset <= len(e.content) {
e.content = e.content[:offset] + text + e.content[offset:]
}
}
func (e *TextEditor) Undo() bool {
if len(e.history) > 0 {
lastIdx := len(e.history) - 1
e.content = e.history[lastIdx]
e.history = e.history[:lastIdx]
return true
}
return false
}
3.2 处理透传变量
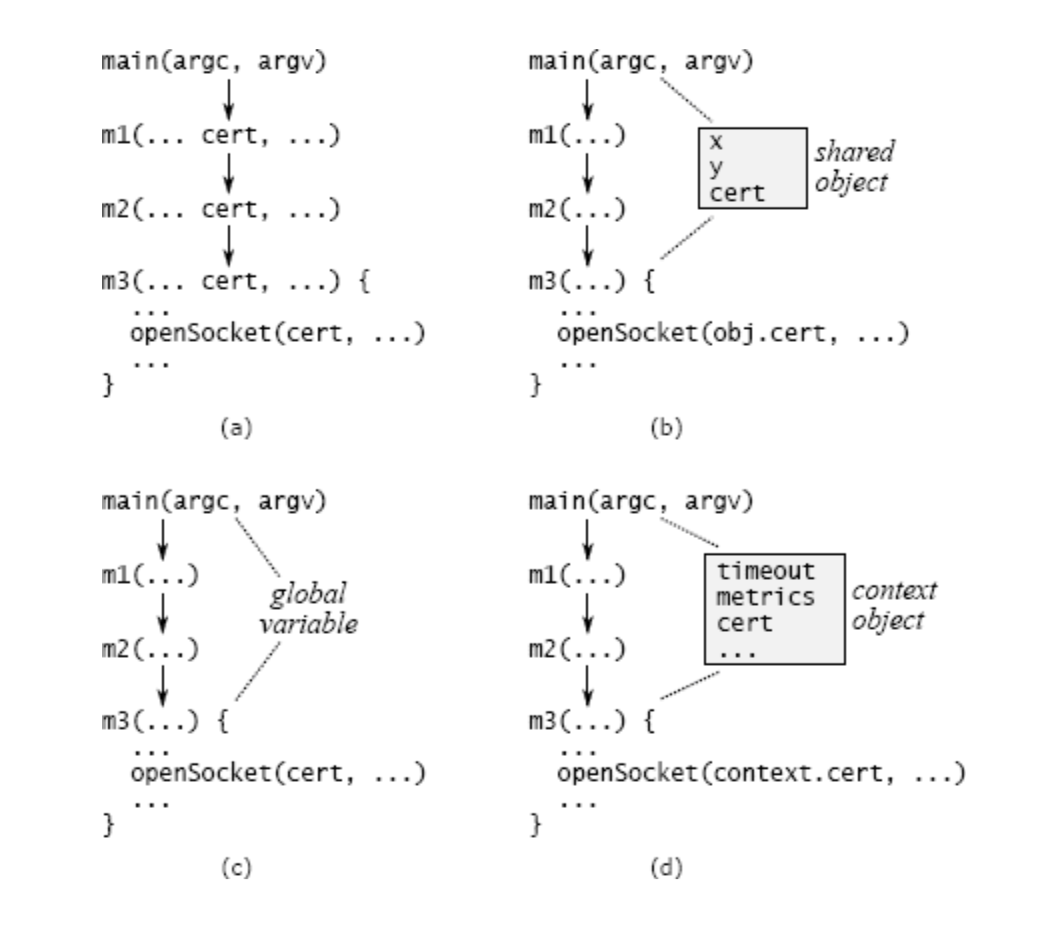
可采用以下几种方式:
-
利用共享对象:如果顶层和底层方法已共享某对象,可将信息存储在该对象中
-
使用全局变量:避免方法间传递,但会导致其他问题
-
引入上下文对象(推荐):
- 创建专门存储所有系统全局状态的上下文对象
- 在主要对象中保存对上下文的引用
- 只在构造函数中显式传递上下文
// 配置类型
type CertificateConfig struct {
CertPath string
KeyPath string
}
// 最顶层方法
func main() {
// 从命令行获取证书配置
certConfig := CertificateConfig{
CertPath: "/path/to/cert.pem",
KeyPath: "/path/to/key.pem",
}
// certConfig 作为透传变量,通过整个调用链传递
startServer(certConfig)
}
func startServer(certConfig CertificateConfig) {
// 并不使用 certConfig,只是传递
initializeServer(certConfig)
}
func initializeServer(certConfig CertificateConfig) {
// 并不使用 certConfig,只是传递
setupConnections(certConfig)
}
func setupConnections(certConfig CertificateConfig) {
// 最终在这里使用 certConfig
openSecureSocket(certConfig)
}
func openSecureSocket(certConfig CertificateConfig) {
// 这里才真正使用证书配置
println("Opening secure socket with cert:", certConfig.CertPath)
println("and key:", certConfig.KeyPath)
}
// 服务器上下文对象
type ServerContext struct {
CertConfig CertificateConfig
// 其他配置...
}
func main() {
// 创建共享的上下文对象
ctx := ServerContext{
CertConfig: CertificateConfig{
CertPath: "/path/to/cert.pem",
KeyPath: "/path/to/key.pem",
},
}
// 只传递上下文
startServer(ctx)
}
func startServer(ctx ServerContext) {
initializeServer(ctx)
}
func initializeServer(ctx ServerContext) {
setupConnections(ctx)
}
func setupConnections(ctx ServerContext) {
openSecureSocket(ctx.CertConfig)
}
func openSecureSocket(certConfig CertificateConfig) {
println("Opening secure socket with cert:", certConfig.CertPath)
println("and key:", certConfig.KeyPath)
}
// 上下文对象
type AppContext struct {
CertConfig CertificateConfig
Timeout int
PerformanceCounter map[string]int
// 其他全局状态...
}
// 服务器类,存储对上下文的引用
type Server struct {
ctx *AppContext
}
func NewServer(ctx *AppContext) *Server {
return &Server{ctx: ctx}
}
func (s *Server) Start() {
s.initialize()
}
func (s *Server) initialize() {
s.setupConnections()
}
func (s *Server) setupConnections() {
// 直接从存储的上下文获取配置,不需要透传
s.openSecureSocket()
}
func (s *Server) openSecureSocket() {
// 直接访问上下文中的证书配置
certConfig := s.ctx.CertConfig
println("Opening secure socket with cert:", certConfig.CertPath)
println("and key:", certConfig.KeyPath)
}
func main() {
// 创建应用上下文
ctx := &AppContext{
CertConfig: CertificateConfig{
CertPath: "/path/to/cert.pem",
KeyPath: "/path/to/key.pem",
},
Timeout: 30,
}
// 创建服务器并启动
server := NewServer(ctx)
server.Start()
}
4. 特殊情况:何时接口重复是可接受的
不是所有相同签名的方法都有问题。关键在于每个新方法是否提供重要的新功能:
- 调度器(Dispatcher):虽然签名相同,但负责根据参数选择合适的方法执行任务
- 多重实现的接口:如操作系统中的磁盘驱动程序,针对不同设备提供相同接口
5. 装饰器模式的注意事项
装饰器模式(Decorator)会导致API跨层重复:
- 特点:提供与底层对象相同或相似的API,同时扩展其功能
- 问题:装饰器类通常很浅,为了实现少量新功能引入大量样板代码
- 替代方案:
- 直接将新功能添加到底层类
- 将特定用例功能与用例合并
- 与现有装饰器合并
- 实现为独立的非包装类
// 基本窗口接口
type Window interface {
Draw()
GetWidth() int
GetHeight() int
HandleClick(x, y int)
}
// 基本窗口实现
type BasicWindow struct {
width, height int
content string
}
func (w *BasicWindow) Draw() {
println("Drawing window with content:", w.content)
}
func (w *BasicWindow) GetWidth() int {
return w.width
}
func (w *BasicWindow) GetHeight() int {
return w.height
}
func (w *BasicWindow) HandleClick(x, y int) {
println("Clicked at:", x, y)
}
// 装饰器:滚动窗口
type ScrollableWindow struct {
window Window // 包装的窗口
scrollX, scrollY int
}
// 透传同时添加功能
func (s *ScrollableWindow) Draw() {
s.window.Draw()
println("Drawing scrollbars at position:", s.scrollX, s.scrollY)
}
// 透传方法
func (s *ScrollableWindow) GetWidth() int {
return s.window.GetWidth()
}
// 透传方法
func (s *ScrollableWindow) GetHeight() int {
return s.window.GetHeight()
}
// 透传同时添加功能
func (s *ScrollableWindow) HandleClick(x, y int) {
// 检查是否点击了滚动条
if isScrollbarClick(x, y) {
println("Adjusting scroll position")
return
}
s.window.HandleClick(x, y)
}
// 再增加一个装饰器:边框窗口
type BorderedWindow struct {
window Window
borderWidth int
}
// 透传同时添加功能
func (b *BorderedWindow) Draw() {
b.window.Draw()
println("Drawing border with width:", b.borderWidth)
}
// 透传方法
func (b *BorderedWindow) GetWidth() int {
return b.window.GetWidth() + 2 * b.borderWidth
}
// 透传方法
func (b *BorderedWindow) GetHeight() int {
return b.window.GetHeight() + 2 * b.borderWidth
}
// 透传同时添加功能
func (b *BorderedWindow) HandleClick(x, y int) {
// 调整坐标以考虑边框
if x < b.borderWidth || y < b.borderWidth ||
x >= b.GetWidth()-b.borderWidth || y >= b.GetHeight()-b.borderWidth {
println("Clicked on border")
return
}
// 传递调整后的坐标
b.window.HandleClick(x - b.borderWidth, y - b.borderWidth)
}
// 客户端代码变得复杂且有许多透传调用
func main() {
basicWindow := &BasicWindow{width: 100, height: 80, content: "Hello"}
scrollable := &ScrollableWindow{window: basicWindow, scrollX: 0, scrollY: 0}
bordered := &BorderedWindow{window: scrollable, borderWidth: 5}
// 使用最终的装饰后窗口
bordered.Draw() // 调用会级联通过多个装饰器
}
func isScrollbarClick(x, y int) bool {
// 判断点击是否在滚动条上
return false // 简化实现
}
// 更好的设计:整合功能,避免多层装饰
type EnhancedWindow struct {
width, height int
content string
hasScrollbars bool
scrollX, scrollY int
hasBorder bool
borderWidth int
}
func (w *EnhancedWindow) Draw() {
println("Drawing window with content:", w.content)
if w.hasBorder {
println("Drawing border with width:", w.borderWidth)
}
if w.hasScrollbars {
println("Drawing scrollbars at position:", w.scrollX, w.scrollY)
}
}
func (w *EnhancedWindow) GetWidth() int {
totalWidth := w.width
if w.hasBorder {
totalWidth += 2 * w.borderWidth
}
return totalWidth
}
func (w *EnhancedWindow) GetHeight() int {
totalHeight := w.height
if w.hasBorder {
totalHeight += 2 * w.borderWidth
}
return totalHeight
}
func (w *EnhancedWindow) HandleClick(x, y int) {
// 处理边框点击
if w.hasBorder {
if x < w.borderWidth || y < w.borderWidth ||
x >= w.GetWidth()-w.borderWidth || y >= w.GetHeight()-w.borderWidth {
println("Clicked on border")
return
}
}
// 处理滚动条点击
if w.hasScrollbars && isScrollbarArea(x, y) {
println("Adjusting scroll position")
return
}
// 处理内容区域点击
effectiveX, effectiveY := x, y
if w.hasBorder {
effectiveX -= w.borderWidth
effectiveY -= w.borderWidth
}
println("Clicked content at:", effectiveX, effectiveY)
}
// 使用构建器模式创建窗口
type WindowBuilder struct {
window *EnhancedWindow
}
func NewWindowBuilder() *WindowBuilder {
return &WindowBuilder{
window: &EnhancedWindow{
width: 100,
height: 80,
content: "Default content",
},
}
}
func (b *WindowBuilder) WithSize(width, height int) *WindowBuilder {
b.window.width = width
b.window.height = height
return b
}
func (b *WindowBuilder) WithContent(content string) *WindowBuilder {
b.window.content = content
return b
}
func (b *WindowBuilder) WithScrollbars() *WindowBuilder {
b.window.hasScrollbars = true
return b
}
func (b *WindowBuilder) WithBorder(width int) *WindowBuilder {
b.window.hasBorder = true
b.window.borderWidth = width
return b
}
func (b *WindowBuilder) Build() *EnhancedWindow {
return b.window
}
// 更简洁的客户端代码
func main() {
window := NewWindowBuilder().
WithSize(100, 80).
WithContent("Hello World").
WithScrollbars().
WithBorder(5).
Build()
window.Draw() // 一次调用完成所有绘制
}
func isScrollbarArea(x, y int) bool {
// 判断是否在滚动条区域
return false // 简化实现
}
6. 接口与实现的分离
类的接口应该与其实现不同:内部使用的表示形式应与接口中出现的抽象不同。如果两者使用相似抽象,则该类可能不够深。
- 示例:文本编辑器中,内部按行存储文本但提供字符级操作接口比提供完全基于行的API更有价值
// 不好的设计:接口反映了内部实现(基于行)
type TextStorage struct {
lines []string
}
// 基于行的API暴露了实现细节
func (t *TextStorage) GetLine(lineNum int) string {
if lineNum < len(t.lines) {
return t.lines[lineNum]
}
return ""
}
func (t *TextStorage) SetLine(lineNum int, content string) {
if lineNum < len(t.lines) {
t.lines[lineNum] = content
}
}
// 客户端代码被迫处理行拆分/合并的复杂性
func clientCode(storage *TextStorage) {
// 在第一行中间插入文本,客户端需要处理拆分行的复杂性
line := storage.GetLine(0)
pos := 5
newLine := line[:pos] + "inserted text" + line[pos:]
storage.SetLine(0, newLine)
// 删除跨行的文本也很复杂...需要处理多行逻辑
}
// 更好的设计:接口独立于内部实现
type TextBuffer struct {
lines []string // 内部仍基于行存储
}
// 提供基于字符位置的接口,隐藏基于行的实现细节
func (t *TextBuffer) Insert(pos int, text string) {
// 内部处理行的拆分和合并
lineNum, linePos := t.translatePosition(pos)
// 处理插入可能跨越多行的情况
currentLine := t.lines[lineNum]
beforeInsert := currentLine[:linePos]
afterInsert := currentLine[linePos:]
// 处理文本中的换行符
textLines := splitLines(text)
if len(textLines) == 1 {
// 简单插入,没有新行
t.lines[lineNum] = beforeInsert + textLines[0] + afterInsert
} else {
// 处理多行插入
newLines := make([]string, 0)
newLines = append(newLines, beforeInsert+textLines[0])
newLines = append(newLines, textLines[1:len(textLines)-1]...)
newLines = append(newLines, textLines[len(textLines)-1]+afterInsert)
// 更新行数组
t.lines = append(t.lines[:lineNum], append(newLines, t.lines[lineNum+1:]...)...)
}
}
func (t *TextBuffer) Delete(startPos, endPos int) {
// 内部处理行的合并
startLine, startLinePos := t.translatePosition(startPos)
endLine, endLinePos := t.translatePosition(endPos)
if startLine == endLine {
// 删除同一行内的文本
line := t.lines[startLine]
t.lines[startLine] = line[:startLinePos] + line[endLinePos:]
} else {
// 处理跨行删除
firstLinePart := t.lines[startLine][:startLinePos]
lastLinePart := t.lines[endLine][endLinePos:]
// 合并首尾行
t.lines[startLine] = firstLinePart + lastLinePart
// 移除中间行
t.lines = append(t.lines[:startLine+1], t.lines[endLine+1:]...)
}
}
// 辅助方法:将绝对位置转换为行和列
func (t *TextBuffer) translatePosition(pos int) (line, col int) {
// 实现位置转换逻辑
charCount := 0
for i, lineText := range t.lines {
lineLen := len(lineText) + 1 // +1 是换行符
if charCount + lineLen > pos {
return i, pos - charCount
}
charCount += lineLen
}
// 默认返回最后一行的末尾
return len(t.lines)-1, len(t.lines[len(t.lines)-1])
}
// 辅助函数:按行分割文本
func splitLines(text string) []string {
// 实现文本行分割
return strings.Split(text, "\n")
}
// 客户端代码变得简单多了
func clientCode(buffer *TextBuffer) {
// 在位置10处插入文本,不需要关心行拆分
buffer.Insert(10, "inserted text")
// 删除从位置5到15的文本,不需要处理跨行逻辑
buffer.Delete(5, 15)
}
第8章 降低复杂性¶
关键结论
当开发模块时,寻找机会让自己多承担一些痛苦,以减轻用户的负担。这通常意味着:
- 实现更复杂但具有简单接口的模块
- 避免不必要的配置参数
- 处理而非传递异常
- 始终关注整体系统复杂性的降低
记住这句话:"模块拥有简单的接口比拥有简单的实现更重要"。
1. 核心思想
本章提出了一个创建更深层次类的关键原则:复杂性应该向下推移。当模块开发中遇到不可避免的复杂性时,应该由模块内部处理这种复杂性,而不是将其暴露给模块的使用者。
这一原则基于一个简单的观察:
- 大多数模块的使用者数量远多于开发者数量
- 因此,让少数开发者承担复杂性比让众多使用者承担更为合理
- 表达这个思想的另一种方式:模块拥有简单的接口比拥有简单的实现更重要
2. 开发者的常见误区
作为开发者,我们经常会做出相反的选择:
| 错误的做法 | 描述 | 后果 |
|---|---|---|
| 抛出异常而非处理 | 遇到不确定如何处理的情况时,简单地抛出异常让调用者处理 | 每个调用者都必须处理这个异常,复杂性被放大 |
| 过度使用配置参数 | 不确定要实施什么策略时,创建配置参数让用户或管理员决定 | 所有系统管理员都必须学习如何设置这些参数 |
这些做法虽然短期内使开发更容易,但会导致复杂性的放大,使多人而非一人必须处理问题。
3. 案例分析
3.1 文本编辑器的文本类
// 向上推移复杂性:简单实现但复杂使用
type LineBasedText struct {
lines []string
}
func (t *LineBasedText) GetLine(lineNum int) string {
if lineNum < len(t.lines) {
return t.lines[lineNum]
}
return ""
}
func (t *LineBasedText) SetLine(lineNum int, content string) {
if lineNum < len(t.lines) {
t.lines[lineNum] = content
}
}
// 调用代码必须处理行的拆分和合并
func handleUserKeypress(text *LineBasedText, position Position, char rune) {
// 获取当前行
line := text.GetLine(position.line)
// 在指定位置插入字符
newLine := line[:position.column] + string(char) + line[position.column:]
// 更新行
text.SetLine(position.line, newLine)
}
// 进行跨行操作更加复杂
func deleteSelection(text *LineBasedText, start, end Position) {
// 删除在同一行内
if start.line == end.line {
line := text.GetLine(start.line)
newLine := line[:start.column] + line[end.column:]
text.SetLine(start.line, newLine)
return
}
// 跨行删除需要合并行
firstLine := text.GetLine(start.line)
lastLine := text.GetLine(end.line)
newLine := firstLine[:start.column] + lastLine[end.column:]
text.SetLine(start.line, newLine)
// 移除中间行的复杂逻辑...
// ...
}
// 向下推移复杂性:实现更复杂但使用更简单
type CharacterBasedText struct {
// 内部仍然基于行存储
lines []string
}
func (t *CharacterBasedText) Insert(pos int, text string) {
// 复杂的插入逻辑被封装在此方法内
lineNum, linePos := t.positionToLineAndColumn(pos)
// 处理可能跨行的插入
if !strings.Contains(text, "\n") {
// 简单插入不涉及新行
line := t.lines[lineNum]
t.lines[lineNum] = line[:linePos] + text + line[linePos:]
return
}
// 处理跨行插入的复杂逻辑
// ...
}
func (t *CharacterBasedText) Delete(startPos, endPos int) {
// 复杂的删除逻辑被封装在此方法内
startLine, startCol := t.positionToLineAndColumn(startPos)
endLine, endCol := t.positionToLineAndColumn(endPos)
// 封装了跨行删除的所有复杂性
// ...
}
// 调用代码变得简单
func handleUserKeypress(text *CharacterBasedText, position int, char rune) {
text.Insert(position, string(char))
}
func deleteSelection(text *CharacterBasedText, start, end int) {
text.Delete(start, end)
}
这个例子展示了:
- 行级接口将复杂性推给了上层模块,导致用户界面代码必须处理行的拆分和合并
- 字符级接口将复杂性下推到文本类内部,简化了上层代码
- 虽然字符级接口使文本类的实现更复杂,但这种复杂性被封装,降低了系统整体复杂度
3.2 配置参数的问题
配置参数是向上推移复杂性的典型例子:
// 使用配置参数的网络客户端
type NetworkClient struct {
// 暴露多个配置参数
RetryCount int // 重试次数
RetryInterval int // 重试间隔(毫秒)
ConnectionTimeout int // 连接超时(毫秒)
ReadTimeout int // 读取超时(毫秒)
WriteTimeout int // 写入超时(毫秒)
}
func NewNetworkClient() *NetworkClient {
return &NetworkClient{
RetryCount: 3, // 默认值
RetryInterval: 1000, // 默认1秒
ConnectionTimeout: 5000,
ReadTimeout: 3000,
WriteTimeout: 3000,
}
}
func (c *NetworkClient) SendRequest(req *Request) (*Response, error) {
var lastErr error
for i := 0; i <= c.RetryCount; i++ {
// 使用配置的超时设置
conn, err := dialWithTimeout(req.URL, c.ConnectionTimeout)
if err != nil {
lastErr = err
time.Sleep(time.Duration(c.RetryInterval) * time.Millisecond)
continue
}
// 设置读写超时
conn.SetReadTimeout(c.ReadTimeout)
conn.SetWriteTimeout(c.WriteTimeout)
// 发送请求逻辑...
// ...
return response, nil
}
return nil, fmt.Errorf("failed after %d retries: %v", c.RetryCount, lastErr)
}
// 使用者必须决定正确的值
func main() {
client := NewNetworkClient()
client.RetryCount = 5
client.RetryInterval = 2000
response, err := client.SendRequest(newRequest())
// ...
}
// 自适应设计的网络客户端
type AdaptiveNetworkClient struct {
// 隐藏了大部分复杂性
responseTimeHistory []time.Duration
historyMutex sync.Mutex
}
func NewAdaptiveNetworkClient() *AdaptiveNetworkClient {
return &AdaptiveNetworkClient{
responseTimeHistory: make([]time.Duration, 0, 10),
}
}
func (c *AdaptiveNetworkClient) SendRequest(req *Request) (*Response, error) {
// 计算当前条件下的最优重试间隔
retryInterval := c.calculateOptimalRetryInterval()
// 计算最佳重试次数基于网络状况
retryCount := c.calculateOptimalRetryCount()
var lastErr error
startTime := time.Now()
for i := 0; i <= retryCount; i++ {
// 自动设置合理的超时时间
timeout := c.calculateTimeout()
conn, err := dialWithTimeout(req.URL, timeout)
if err != nil {
lastErr = err
time.Sleep(retryInterval)
continue
}
// 发送请求逻辑...
// ...
// 记录响应时间用于未来调整
duration := time.Since(startTime)
c.recordResponseTime(duration)
return response, nil
}
return nil, fmt.Errorf("failed after %d retries: %v", retryCount, lastErr)
}
func (c *AdaptiveNetworkClient) calculateOptimalRetryInterval() time.Duration {
c.historyMutex.Lock()
defer c.historyMutex.Unlock()
if len(c.responseTimeHistory) == 0 {
return 1 * time.Second // 默认值
}
// 基于历史响应时间计算最佳间隔
// ...
return optimalInterval
}
// 其它自适应方法...
// 使用者不需要设置参数
func main() {
client := NewAdaptiveNetworkClient()
response, err := client.SendRequest(newRequest())
// ...
}
这个对比说明:
- 配置参数让用户必须决定正确的值,这通常很困难
- 自适应设计通过观察系统行为自动调整参数,下推了复杂性
- 自适应方法还能根据操作条件变化动态调整,而配置参数往往变得过时
3.3 配置参数的取舍
| 优势 | 劣势 |
|---|---|
| 允许用户根据特定需求调整系统 | 用户/管理员难以确定正确值 |
| 适用于领域知识在用户而非代码中的情况 | 成为逃避实现完整解决方案的借口 |
| 可以适应不同工作负载 | 参数容易过时 |
| 增加了文档和学习成本 |
4. 限制与平衡
向下推移复杂性并非万能,需要谨慎应用:
- 不应极端地将所有功能下推到单个类中
- 下推复杂性最有意义的条件:
- 被下推的复杂性与类现有功能密切相关
- 下推会显著简化应用中的其他部分
- 下推简化了类的接口
- 目标是最小化整体系统复杂性,而非局部优化
错误示例:在文本类中添加实现退格键功能的方法。虽然这下推了复杂性,但它:
- 不会显著简化高层代码
- 用户界面知识与文本类核心功能无关
- 导致了不必要的信息泄漏