01-06¶
1. 整洁代码¶
- 记住,代码确然是我们最终用来表达需求的那种语言。我们可以创造各种与需求接近的语言。我们可以创造帮助把需求解析和汇整为正式结构的各种工具。然而,我们永远无法抛弃必要的精确性——所以代码永存
- 我们都曾经瞟一眼自己亲手造成的混乱,决定弃之而不顾,走向新一天。我们都曾经看到自己的烂程序居然能运行,然后断言能运行的烂程序总比什么都没有强。我们都曾经说过有朝一日再回头清理。当然,在那些日子里,我们都没听过勒布朗(LeBlanc)法则:稍后等于永不(Later equals never)
- 随着混乱的增加,团队生产力也持续下降,趋向于零。当生产力下降时,管理层就只有一件事可做了:增加更多人手到项目中,期望提升生产力。可是新人并不熟悉系统的设计。他们搞不清楚什么样的修改符合设计意图,什么样的修改违背设计意图。而且,他们以及团队中的其他人都背负着提升生产力的可怕压力。于是,他们制造更多的混乱,驱动生产力向零那端不断下降
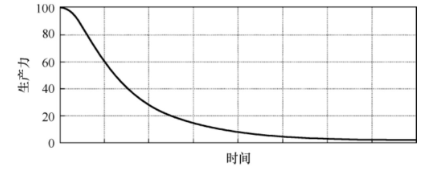
- 花时间保持代码整洁不但有关效率,还有关生存
- 我们与项目的规划脱不了干系,对失败负有极大的责任;特别是当失败与糟糕的代码有关时尤为如此!
- 多数经理想要知道实情,即便他们看起来不喜欢实情。多数经理想要好代码,即便他们总是痴缠于进度。他们会奋力卫护进度和需求;那是他们该干的。你则当以同等的热情卫护代码。程序员遵从不了解混乱风险的经理的意愿,也是不专业的做法
- 混乱只会立刻拖慢你,叫你错过期限。赶上期限的唯一方法——做得快的唯一方法——就是始终尽可能保持代码整洁
- 写整洁代码,需要遵循大量的小技巧,贯彻刻苦习得的“整洁感”。这种“代码感”就是关键所在。有些人生而有之。有些人费点劲才能得到。它不仅让我们看到代码的优劣,还予我们以借戒规之力化劣为优的攻略
什么是整洁的代码
Bjarne Stroustrup:
“我喜欢优雅和高效的代码。代码逻辑应当直截了当,叫缺陷难以隐藏;尽量减少依赖关系,使之便于维护;依据某种分层战略完善错误处理代码;性能调至最优,省得引诱别人做没规矩的优化,搞出一堆混乱来。整洁的代码只做好一件事。”
Grady Booch:
“整洁的代码简单直接。整洁的代码如同优美的散文。整洁的代码从不隐藏设计者的意图,充满了干净利落的抽象和直截了当的控制语句。”
Dave Thomas:
“整洁的代码应可由作者之外的开发者阅读和增补。它应当有单元测试和验收测试。它使用有意义的命名。它只提供一种而非多种做一件事的途径。它只有尽量少的依赖关系,而且要明确地定义和提供清晰、尽量少的API。代码应通过其字面表达含义,因为不同的语言导致并非所有必需信息均可通过代码自身清晰表达。”
Michael Feathers:
“我可以列出我留意到的整洁代码的所有特点,但其中有一条是根本性的。整洁的代码总是看起来像是某位特别在意它的人写的。几乎没有改进的余地。代码作者什么都想到了,如果你企图改进它,总会回到原点,赞叹某人留给你的代码——全心投入的某人留下的代码。”
Ron Jeffries:
“近年来,我开始研究贝克的简单代码规则,差不多也都琢磨透了。简单代码,依其重要顺序:
- 能通过所有测试;
- 没有重复代码;
- 体现系统中的全部设计理念;
- 包括尽量少的实体,比如类、方法、函数等。
在以上诸项中,我最在意代码重复。如果同一段代码反复出现,就表示某种想法未在代码中得到良好的体现。我尽力去找出到底那是什么,然后再尽力更清晰地表达出来。
在我看来,有意义的命名是体现表达力的一种方式,我往往会修改好几次才会定下名字来。借助Eclipse这样的现代编码工具,重命名代价极低,所以我无所顾忌。然而,表达力还不只体现在命名上。我也会检查对象或方法是否想做的事太多。如果对象功能太多,最好是切分为两个或多个对象。如果方法功能太多,我总是使用抽取手段(Extract Method)重构之,从而得到一个能较为清晰地说明自身功能的方法,以及另外数个说明如何实现这些功能的方法。
消除重复和提高表达力让我在整洁代码方面获益良多,只要铭记这两点,改进脏代码时就会大有不同。不过,我时常关注的另一规则就不太好解释了。
这么多年下来,我发现所有程序都由极为相似的元素构成。例如“在集合中查找某物”。不管是雇员记录数据库还是名-值对哈希表,或者某类条目的数组,我们都会发现自己想要从集合中找到某一特定条目。一旦出现这种情况,我通常会把实现手段封装到更抽象的方法或类中。这样做好处多多。
可以先用某种简单的手段,比如哈希表来实现这一功能,由于对搜索功能的引用指向了我那个小小的抽象,就能随需应变,修改实现手段。这样就既能快速前进,又能为未来的修改预留余地。
另外,该集合抽象常常提醒我留意“真正”在发生的事,避免随意实现集合行为,因为我真正需要的不过是某种简单的查找手段。
减少重复代码,提高表达力,提早构建简单抽象。这就是我写整洁代码的方法。”
Ward Cunningham:
“如果每个例程都让你感到深合己意,那就是整洁代码。如果代码让编程语言看起来像是专为解决那个问题而存在,就可以称之为漂亮的代码。”
- 你该明白了。读与写花费时间的比例超过10:1。写新代码时,我们一直在读旧代码。编写代码的难度,取决于读周边代码的难度。要想干得快,要想早点做完,要想轻松写代码,先让代码易读吧
- 光把代码写好可不够。必须时时保持代码整洁。我们都见过代码随时间流逝而腐坏。我们应当更积极地阻止腐坏的发生。
小结
艺术书并不保证你读过之后能成为艺术家,只能告诉你其他艺术家用过的工具、技术和思维过程。本书同样也不担保让你成为好程序员。它不担保能给你代码感”。它所能做的,只是展示好程序员的思维过程,还有他们使用的技巧、技术和工具。
和艺术书一样,本书也充满了细节。代码会很多。你会看到好代码,也会看到糟糕的代码。你会看到糟糕的代码如何转化为好代码。你会看到启发、规条和技巧的列表。你会看到一个又一个例子。但最终结果取决于你自己。
还记得那个关于小提琴家在去表演的路上迷路的老笑话吗?他在街角拦住一位长者,问他怎么才能去卡耐基音乐厅(Carnegie Hall)。长者看了看小提琴家,又看了看他手中的琴,说道:“你还得练,孩子,还得练!
2. 有意义的命名¶
Quote
“既然有这么多命名要做,不妨做好它。”
1. 名副其实
- 选个好名字要花时间,但省下来的时间比花掉的多。注意命名,而且一旦发现有更好的名称,就换掉旧的。这么做,读你代码的人(包括你自己)都会更开心。
- 如果名称需要注释来补充,那就不算是名副其实。
- 选择体现本意的名称能让人更容易理解和修改代码。
- 问题不在于代码的简洁度,而是在于代码的模糊度:即上下文在代码中未被明确体现的程度。
2. 避免误导
- 程序员必须避免留下掩藏代码本意的错误线索。应当避免使用与本意相悖的词。
- 提防使用不同之处较小的名称。
- 以同样的方式拼写出同样的概念才是信息。拼写前后不一致就是误导。
3. 做有意义的区分
- 如果程序员只是为满足编译器或解释器的需要而写代码,就会制造麻烦。
- 废话是另一种没意义的区分。
- 注意,只要体现出有意义的区分,使用 a 和 the 这样的前缀就没错。
- 废话都是冗余。
- 要区分名称,就要以读者能鉴别不同之处的方式来区分。
4. 使用读得出来的名称
- 这不是小事,因为编程本就是一种社会活动。
5. 使用可搜索的名称
- 长名称胜于短名称,搜得到的名称胜于用自造编码代写就的名称。
- 若变量或常量可能在代码中多处使用,则应赋其以便于搜索的名称。
6. 避免使用编码
- 把类型或作用域编进名称里面,徒然增加了解码的负担。
- 如今HN和其他类型编码形式都纯属多余。
- 也不必用 m_前缀来标明成员变量。应当把类和函数做得足够小,消除对成员前缀的需要。
- 前缀变作了不入法眼的废料,变作了旧代码的标志物。
- 如果接口和实现必须选一个来编码的话,我宁肯选择实现。ShapeFactoryImp,甚至是丑陋的CShapeFactory,都比对接口名称编码来得好。
7. 避免思维映射
- 不应当让读者在脑中把你的名称翻译为他们熟知的名称。这种问题经常出现在选择是使用问题领域术语还是解决方案领域术语时。
- 程序员通常都是聪明人。聪明人有时会借脑筋急转弯炫耀其聪明。
- 聪明程序员和专业程序员之间的区别在于,专业程序员了解,明确是王道。专业程序员善用其能,编写其他人能理解的代码。
8. 类名&方法名
- 类名和对象名应该是名词或名词短语。
- 方法名应当是动词或动词短语。
- 重载构造器时,使用描述了参数的静态工厂方法名。
9. 别抖机灵
- 如果名称太耍宝,那就只有同作者一般有幽默感的人才能记得住,而且还是在他们记得那个笑话的时候才行。
- 言到意到。意到言到。
10. 每个概念对应一个词
- 给每个抽象概念选一个词,并且一以贯之。
- 函数名称应当独一无二,而且要保持一致,这样你才能不借助多余的浏览就找到正确的方法。
11. 别用双关语
- 避免将同一单词用于不同目的。
- 代码作者应尽力写出易于理解的代码。我们想把代码写得让别人能一目尽览,而不必殚精竭虑地研究。我们想要那种大众化的作者尽责写清楚的平装书模式;我们不想要那种学者挖地三尺才能明白个中意义的学院派模式。
12. 使用解决方案领域名称
- 记住,只有程序员才会读你的代码。
- 程序员要做太多技术性工作。给这些事取个技术性的名称,通常是最靠谱的做法。
13. 使用源自所涉问题领域的名称
- 如果不能用程序员熟悉的术语来给手头的工作命名,就采用从所涉问题领域而来的名称吧。
- 与所涉问题领域更为贴近的代码,应当采用源自问题领域的名称。
14. 添加有意义的语境&不要添加没用的语境
- 很少有名称是能自我说明的——多数都不能。反之,你需要用有良好命名的类、函数或名称空间来放置名称,给读者提供语境。如果没这么做,给名称添加前缀就是最后一招了。
- 语境的增强也让算法能够通过分解为更小的函数而变得更为干净利落。
- 只要短名称足够清楚,就要比长名称好。别给名称添加不必要的语境。
- 精确正是命名的要点。
最后的话
取好名字最难的地方在于需要良好的描述技巧和共有文化背景。与其说这是一种技术、商业或管理问题,还不如说是一种教学问题。其结果是,这个领域内的许多人都没能学会做得很好。
3. 函数¶
函数是所有程序中的第一组代码。
3.1 短小¶
- 函数的第一规则是要短小。第二条规则是还要更短小。 经过漫长的试错,经验告诉我们,函数就该小。
- 每个函数都一目了然。每个函数都只说一件事。而且每个函数都依序把你带到下一个函数,这就是函数应该达到的短小程度。
- if语句、else语句、while语句等,其中的代码块应该只有一行。 该行大抵应该是一个函数调用语句。 这样不但能保持函数短小,而且因为块内调用的函数拥有较具说明性的名称,从而增加了文档上的价值。
3.2 只做一件事¶
- 函数应该做一件事。做好这件事。只做这一件事。
- 如果函数只是做了该函数名下同一抽象层上的步骤,则函数还是只做了一件事。 编写函数毕竟是为了把大一些的概念(换言之,函数的名称)拆分为另一抽象层上的一系列步骤。
- 所以,要判断函数是否不止做了一件事还有一个方法,就是看是否能再拆出一个函数, 该函数不仅只是单纯地重新诠释其实现。
- 只做一件事的函数无法被合理地切分为多个区段。 这就是函数做事太多的明显征兆。
3.3 每个函数一个抽象层级¶
- 要确保函数只做一件事,函数中的语句都要在同一抽象层级上。
- 函数中混杂不同抽象层级,往往让人迷惑。 读者可能无法判断某个表达式是基础概念还是细节。更恶劣的是,一旦细节与基础概念混杂,更多的细节就会在函数中纠结起来。
- 我们想要让代码拥有自顶向下的阅读顺序。我们想要让每个函数后面都跟着位于下一抽象层级的函数,这样一来,在查看函数列表时,就能偱抽象层级向下阅读了。即叫做做向下规则。
- 让代码读起来像是一系列自顶向下的To起头段落是保持抽象层级协调一致的有效技巧。
3.4 switch语句¶
- 写出短小的switch语句很难。即便是只有两种条件的switch语句也要比想要的单个代码块或函数大得多。写出只做一件事的switch语句也很难。Switch天生要做N件事。不幸我们总无法避开switch语句,不过还是能够确保每个switch都埋藏在较低的抽象层级,而且永远不重复。当然可利用多态来实现这一点。
- 对于switch语句,我的规矩是如果只出现一次,用于创建多态对象,而且隐藏在某个继承关系中,在系统其他部分看不到,就还能容忍。
3.5 使用描述性的名称¶
- 记住沃德原则:“如果每个例程都让你感到深合己意,那就是整洁代码。” 要遵循这一原则,泰半工作都在于为只做一件事的小函数取个好名字。函数越短小、功能越集中,就越便于取个好名字。
- 别害怕长名称。长而具有描述性的名称,要比短而令人费解的名称好。 长而具有描述性的名称,要比描述性的长注释好。使用某种命名约定,让函数名称中的多个单词容易阅读,然后使用这些单词给函数取个能说清其功用的名称。
- 别害怕花时间取名字。你当尝试不同的名称,实测其阅读效果。
- 选择描述性的名称能理清你关于模块的设计思路,并帮你改进之。追索好名称,往往导致对代码的改善重构。
- 命名方式要保持一致。 使用与模块名一脉相承的短语、名词和动词给函数命名。
3.6 函数参数¶
- 最理想的参数数量是零(零参数函数),其次是1(单参数函数),再次是2(双参数函数),应尽量避免3(三参数函数)。有足够特殊的理由才能用3个以上参数(多参数函数)——所以无论如何也不要这么做。
- 参数不易对付。它们带有太多概念性。 参数与函数名处在不同的抽象层级,它要求你了解目前并不特别重要的细节。
- 从测试的角度看,参数甚至更叫人为难。
- 输出参数比输入参数还要难以理解。
- 相较于没有参数,只有一个输入参数算是第二好的做法。
1. 单参数函数的普遍形式
- 你应当选用较能区别这两种理由的名称,而且总在一致的上下文中使用这两种形式。
- 还有虽不那么普遍但仍极有用的单参数函数形式,那就是事件(event)。在这种形式中,有输入参数而无输出参数。小心使用这种形式。应该让读者很清楚地了解它是个事件。谨慎地选用名称和上下文语境。
- 尽量避免编写不遵循这些形式的一元函数。
2. 标识参数
- 标识参数丑陋不堪。 向函数传入布尔值简直就是骇人听闻的做法。这样做,方法签名立刻变得复杂起来,大声宣布本函数不止做一件事。
3. 双参数函数
- 有两个参数的函数要比一元函数难懂。 尽管两种情况下意义都很清楚,但第一个只要扫一眼就明白,更好地表达了其意义。第二个就得暂停一下才能明白,除非我们学会忽略第一个参数。而且最终那也会导致问题,因为我们根本就不该忽略任何代码。忽略掉的部分就是缺陷藏身之地。当然,有些时候两个参数正好。
- 二元函数不算恶劣,而且你当然也会编写二元函数。不过你得小心使用二元函数要付出代价。 你应该尽量利用一些机制将其转换成一元函数。
4. 三参数函数
- 有三个参数的函数要比二元函数难懂得多。 排序、琢磨、忽略的问题都会加倍体现。建议你在写三元函数前一定要想清楚。
5. 参数对象
- 如果函数看来需要两个、三个或三个以上参数,就说明其中一些参数应该封装为类了。
- 从参数创建对象,从而减少参数数量,看起来像是在作弊,但实则并非如此。
6. 参数列表
- 有时我们想要向函数传入数量可变的参数。如果可变参数像上例中那样被同等对待,就和类型为List的单个参数没什么两样。
- 有可变参数的函数可能是一元、二元甚至三元。超过这个数量就可能要犯错了。
7. 动词与关键词
- 给函数取个好名字,能较好地解释函数的意图,以及参数的顺序和意图。 对于一元函数,函数和参数应当形成一种非常良好的动词/名词对形式。
- 最后那个例子展示了函数名称的关键字(keyword)形式。 使用这种形式,我们把参数的名称编码成了函数名。
3.7 无副作用¶
- 副作用是一种谎言。函数承诺只做一件事,但还是会做其他被藏起来的事。 有时它会对自己类中的变量做出未能预期的改动。有时,它会把变量搞成向函数传递的参数或是系统全局变量。无论哪种情况,都是具有破坏性的,会导致古怪的时序性耦合及顺序依赖。
- 这一副作用造出了一次时序性耦合。如果一定要时序性耦合,就应该在函数名称中说明。
- 参数多数会被自然而然地看作是函数的输入。 如果你编过好些年程序,我担保你一定被用作输出而非输入的参数迷惑过。
- 事情清楚了但付出了检查函数声明的代价。你被迫检查函数签名,就得花上一点时间。应该避免这种中断思路的事。
- 普遍而言应避免使用输出参数。 如果函数必须要修改某种状态,就修改所属对象的状态吧。
3.8 分隔指令与询问¶
- 函数要么做什么事,要么回答什么事,但二者不可得兼。 函数应该修改某对象的状态,或是返回该对象的有关信息。两样都干常会导致混乱。
- 真正的解决方案是把指令与询问分隔开来,防止混淆的发生。
3.9 使用异常替代返回错误码¶
- 从指令式函数返回错误码轻微违反了指令与询问分隔的规则。 它鼓励了在if语句判断中把指令当作表达式使用。
- 这不会引起动词/形容词混淆,但却导致更深层次的嵌套结构。当返回错误码时,就是在要求调用者立刻处理错误。
- 如果使用异常替代返回错误码, 错误处理代码就能从主路径代码中分离出来,得到简化。
1. 抽离 try/catch 代码块
- Try/catch代码块丑陋不堪。它们搞乱了代码结构,把错误处理与正常流程混为一谈。最好把try和catch代码块的主体部分抽离出来,另外形成函数。
2. 错误处理就是一件事
- 函数应该只做一件事。错误处理就是一件事。因此,处理错误的函数不该做其他事。
3. Error.java 依赖磁铁
- 这样的类就是一块依赖磁铁(dependency magnet);其他许多类都得导入和使用它。
- 使用异常替代错误码,新异常就可以从异常类派生出来, 无需重新编译或重新部署。
3.10 别重复自己¶
- 这样的重复还是会导致问题,因为代码因此而臃肿, 且当算法改变时需要修改4处地方。而且也会增加4次放过错误的可能性。
- 整个模块的可读性因为重复的消除而得到了提升。 重复可能是软件中一切邪恶的根源。许多原则与实践规则都是为控制与消除重复而创建。
3.11 结构化编程¶
- 有些程序员遵循 Edsger Dijkstra 的结构化编程规则。Dijkstra 认为,每个函数、函数中的每个代码块都应该有一个入口、一个出口。遵循这些规则,意味着在每个函数中只该有一个 return 语句,循环中不能有 break 或 continue 语句,而且永永远远不能有任何 goto 语句。
- 我们赞成结构化编程的目标和规范,但对于小函数,这些规则助益不大。 只有在大函数中,这些规则才会有明显的好处。 所以只要函数保持短小,偶尔出现的 return、break 或 continue 语句没有坏处,甚至还比单入单出原则更具有表达力。另外一方面,goto 只在大函数中才有道理,所以应该尽量避免使用。
3.12 如何写出这样的函数¶
- 写代码和写别的东西很像。在写论文或文章时,你先想什么就写什么,然后再打磨它。初稿也许粗陋无序,你就斟酌推敲,直至达到你心目中的样子。
3.13 小结¶
- 每个系统都是使用某种领域特定语言搭建,而这种语言是程序员设计来描述那个系统的。函数是语言的动词,类是名词。这并非是退回到那种认为需求文档中的名词和动词就是系统中类和函数的最初设想的可怕的旧观念。其实这是个历史更久的真理。编程艺术是且一直就是语言设计的艺术。
- 本章所讲述的是有关编写良好函数的机制。如果你遵循这些规则,函数就会短小,有个好名字,而且被很好地归置。不过永远别忘记,真正的目标在于讲述系统的故事,而你编写的函数必须干净利落地拼装到一起,形成一种精确而清晰的语言,帮助你讲故事。
4. 注释¶
- 什么也比不上放置良好的注释来得有用。什么也不会比乱七八糟的注释更有本事搞乱一个模块。什么也不会比陈旧、提供错误信息的注释更有破坏性。
- 注释并不像辛德勒的名单。它们并不“纯然地好”。实际上注释最多也就是一种必须的恶。
- 注释的恰当用法是弥补我们在用代码表达意图时遭遇的失败。 注意,我用了“失败”一词。我是说真的。注释总是一种失败。我们总无法找到不用注释就能表达自我的方法,所以总要有注释,这并不值得庆贺。
- 注释存在的时间越久,就离其所 描述的代码越远,越来越变得全然错误。原因很简单:程序员不能坚持维护注释。
- 程序员应当负责将注释保持在可维护、有关联、精确的高度。我 同意这种说法。但我更主张把力气用在写清楚代码上,直接保证无须编写注释。 不准确的注释要比没注释坏得多。
- 真实只在一处地方有:代码。 只有代码能忠实地告诉你它做的事。那是唯一真正准确的信息来源。所以,尽管有时也需要注释,我们也该多花心思尽量减少注释量。
4.1 注释不能美化糟糕的代码¶
- 写注释的常见动机之一是糟糕的代码的存在。
- 带有少量注释的整洁而有表达力的代码,要比带有大量注释的零碎而复杂的代码像样得多。
4.2 用代码来阐述¶
- 有时代码本身不足以解释其行为。不幸的是许多程序员据此 以为代码很少——如果有的话——能做好解释工作。这种观点纯属错误。
4.3 好注释¶
- 有些注释是必须的,也是有利的。 来看看一些我认为值得写的注释。不过要记住唯一真正好的注释是你想办法不去写的注释。
1. 法律信息
- 有时,公司代码规范要求编写与法律有关的注释。这类注释不应是合同或法典。只要有可能就指向一份标准许可或其他外部文档, 而不要把所有条款放到注释中。
2. 提供信息的注释
- 有时,用注释来提供基本信息也有其用处。这类注释有时管用,但更好的方式是尽量利用函数名称传达信息。
3. 对意图的解释
- 有时,注释不仅提供了有关实现的有用信息,而且还提供了某个决定后面的意图。
4. 阐释
- 有时,注释把某些晦涩难明的参数或返回值的意义翻译为某种可读形式,也会是有用的。通常更好的方法是尽量让参数或返回值自身就足够清楚;但如果参数或返回值是某个标准库的一部分,或是你不能修改的代码帮助阐释其含义的代码就会有用。
- 这一方面说明了阐释有多必要,另外也说明了它有风险。 所以在写这类注释之前,考虑一下是否还有更好的办法,然后再加倍小心地确认注释正确性。
5. 警示
- 有时,用于警告其他程序员会出现某种后果的注释也是有用的。
6. TODO 注释
- 有时,有理由用//TODO 形式在源代码中放置要做的工作列表。
7. 放大
- 注释可以用来放大某种看来不合理之物的重要性。
8. 公共 API 中的 Javadoc
- 没有什么比被良好描述的公共API更有用和令人满意的了。
4.4 坏注释¶
- 通常,坏注释都是糟糕的代码的支撑或借口,或者对错误决策的修正,基本上等于程序员自说自话。
1. 喃喃自语
- 如果只是因为你觉得应该或者因为过程需要就添加注释,那就是无谓之举。如果你决定写注释,就要花必要的时间确保写出最好的注释。
2. 多余的注释
- 其头部位置的注释全属多余。读这段注释花的时间没准比读代码花的时间还要长。
3. 误导性注释
- 有时,尽管初衷可嘉,程序员还是会写出不够精确的注释。
4. 循规式注释
- 所谓每个函数都要有 Javadoc 或每个变量都要有注释的规矩全然是愚蠢可笑的。这类注释徒然让代码变得散乱,满口胡言令人迷惑不解。
5. 日志式注释
- 很久以前,在模块开始处创建并维护这些记录还算有道理。那时,我们还没有源代码控制系统可用。如今这种冗长的记录只会让模块变得凌乱不堪,应当全部删除。
6. 废话注释
- 这类注释废话连篇,我们都学会了视而不见。读代码时眼光不会停留在它们上面。最终,当代码修改之后这类注释就变作了谎言一堆。
- 与其纠缠于毫无价值的废话注释,程序员应该意识到,他的挫败感可以由改进代码结构而消除。
7. 可怕的废话
- Javadoc也可能是废话。下例 Javadoc 的目的是什么?答案:无。它们只是源自某种提供文档的不当愿望的废话注释。
如果作者在 写(或粘贴)注释时都没花心思,怎么能指望读者从中获益呢?
8. 能用函数或变量时就别用注释
- 作者应该重构代码,如我所做的那样从而删掉注释。
9. 位置标记
- 把特定函数趸放在这种标记栏下面,多数时候实属无理。鸡零狗碎,理当删除——特别是尾部那一长串无用的斜杠。
- 尽量少用标记栏,只在特别有价值的时候用。如果滥用标记栏,就会沉没在背景噪音中被忽略掉。
10. 括号后面的注释
- 有时,程序员会在括号后面放置特殊的注释。尽管这对于含有深度嵌套结构的长函数可能有意义,但只会给我们更愿意编写的短小、封装的函数带来混乱。如果你发现自己想标记右括号,其实应该做的是缩短函数。
11. 归属与署名
- 源代码控制系统非常善于记住是谁在何时添加了什么。没必要用那些小小的签名搞脏代码。
12. 注释掉的代码
- 其他人不敢删除注释掉的代码。他们会想代码依然放在那儿,一定有其原因,而且这段代码很重要,不能删除。注释掉的代码堆积在一起,就像破酒瓶底的渣滓一般。
13. HTML注释
- 如果注释将由某种工具抽取出来,呈现到网页,那么该是工具而非程序员来负责给注释加上合适的HTML标签。
14. 非本地信息
- 假如你一定要写注释,请确保它描述了离它最近的代码。 别在本地注释的上下文环境中给出系统级的信息。
15. 信息过多
- 别在注释中添加有趣的历史性话题或者无关的细节描述。
16. 不明显的联系
- 注释及其描述的代码之间的联系应该显而易见。如果你不嫌麻烦要写注释,至少让读者能看着注释和代码,并且理解注释所谈何物。
17. 函数头
- 短函数不需要太多描述。 为只做一件事的短函数选个好名字,通常要比写函数头注释要好。
18. 非公共代码中的 Javadoc
- 虽然 Javadoc 对于公共 API 非常有用,但对于不打算作公共用途的代码就令人厌恶了。
19. 范例
5. 格式¶
当有人查看底层代码实现时,我们希望他们为其整洁、一致及所感知到的对细节的关注而震惊。我们希望他们高高扬起眉毛,一路看下去。
5.1 格式的目的¶
- 先明确一下代码格式很重要。代码格式不可忽略,必须严肃对待。代码格式关乎沟通,而沟通是专业开发者的头等大事。
- 你今天编写的功能,极有可能在下一版本中被修改,但代码的可读性却会对以后可能发生的修改行为产生深远影响。原始代码修改之后很久,其代码风格和可读性仍会影响到可维护性和扩展性。即便代码已不复存在,你的风格和律条仍存活下来。
5.2 垂直格式¶
- 对我们来说,意味着有可能用大多数为200行、最长500行的单个文件构造出色的系统。尽管这并非不可违背的原则,也应该乐于接受。短文件通常比长文件易于理解。
1. 向报纸学习
- 源文件也要像报纸文章那样。名称应当简单且一目了然。名称本身应该足够告诉我们是否在正确的模块中。源文件最顶部应该给出高层次概念和算法。细节应该往下渐次展开,直至找到源文件中最底层的函数和细节。
2. 概念间垂直方向上的区隔
- 几乎所有的代码都是从上往下读,从左往右读。 每行展现一个表达式或一个子句,每组代码行展示一条完整的思路。这些思路用空白行区隔开来。
- 在封包声明、导入声明和每个函数之间,都有空白行隔开。这条极其简单的规则极大地影响到代码的视觉外观。每个空白行都是一条线索,标识出新的独立概念。
3. 垂直方向上的靠近
- 如果说空白行隔开了概念,靠近的代码行则暗示了它们之间的紧密关系。所以紧密相关的代码应该互相靠近。
4. 垂直距离
- 因为你想要理解系统做什么,但却花时间和精力在找到和记住那些代码碎片在哪里。
- 除非有很好的理由,否则就不要把关系密切的概念放到不同的文件中。 实际上,这也是避免使用protected变量的理由之一。
- 对于那些关系密切、放置于同一源文件中的概念,它们之间的区隔应该成为对相互的易懂度有多重要的衡量标准。应避免迫使读者在源文件和类中跳来跳去。
- 变量声明:变量声明应尽可能靠近其使用位置。
- 实体变量:实体变量应该在类的顶部声明。 这应该不会增加变量的垂直距离,因为在设计良好的类中它们如果不是被该类的所有方法也是被大多数方法所用。
- 相关函数:若某个函数调用了另外一个,就应该把它们放到一起,而且调用者应该尽可能放在被调用者上面。这样程序就有个自然的顺序。注意顶部的函数是如何调用其下的函数,而这些被调用的函数又是如何调用更下面的函数的。这样就能轻易找到被调用的函数,极大地增强了整个模块的可读性。
- 概念相关:概念相关的代码应该放到一起。相关性越强,彼此之间的距离就该越短。相关性应建立在直接依赖的基础上,如函数间调用, 或函数使用某个变量。但也有其他相关性的可能。相关性可能来自于执行相似操作的一组函数。
- 这些函数有着极强的概念相关性,因为他们拥有共同的命名模式,执行同一基础任务的不同变种。互相调用是第二位的。即便没有互相调用,也应该放在一起。
5. 垂直顺序
- 一般而言,我们想自上向下展示函数调用依赖顺序。也就是说被调用的函数应该放在执行调用的函数下面。这样就建立了一种自顶向下贯穿源代码模块的良好信息流。
- 这样,我们就能扫过源代码文件自最前面的几个函数获知要旨,而不至于沉溺到细节中。
5.3 横向格式¶
- 程序员们显然更喜爱短代码行。
- 我一向遵循无需拖动滚动条到右边的原则。
1. 水平方向上的区隔与靠近
- 我们使用空格字符将彼此紧密相关的事物连接到一起,也用空格字符把相关性较弱的事物分隔开。
- 我在赋值操作符周围加上空格字符,以此达到强调目的。赋值语句有两个确定而重要的要素:左边和右边。空格字符加强了分隔效果。另一方面,我不在函数名和左圆括号之间加空格。这是因为函数与其参数密切相关,如果隔开就会显得互无关系。我把函数调用括号中的参数一一隔开,强调逗号,表示参数是互相分离的。
- 空格字符的另一种用法是强调其前面的运算符。
2. 水平对齐
- 我发现这种对齐方式没什么用。对齐,像是在强调不重要的东西,把我的目光从真正的意义上拉开。
- 如果有较长的列表需要做对齐处理,那问题就是在列表的长度上而不是对齐上。
3. 缩进
- 源文件是一种继承结构,而不是一种大纲结构。其中的信息涉及整个文件、文件中每个类、类中的方法、方法中的代码块,也涉及代码块中的代码块。
- 要让这种范围式继承结构可见,我们依源代码行在继承结构中的位置对源代码行做缩进处理。
- 程序员相当依赖这种缩进模式。他们从代码行左边查看自己在什么范围中工作。这让他们能快速跳过与当前关注的情形无关的范围。
- 违反缩进规则。有时,会忍不住想要在短小的 if 语句、while 循环或小函数中违反缩进规则。一旦这么做了我多数时候还是会回头加上缩进。这样就避免了出现以下这种范围层级坍塌到一行的情况。
4. 空范围
- 有时,while或for语句的语句体为空。我不喜欢这种结构,尽量不使用。如果无法避免,就确保空范围体的缩进,用括号包围起来。
5.4 团队规则¶
- 每个程序员都有自己喜欢的格式规则,但如果在一个团队中工作,就是团队说了算。
- 记住,好的软件系统是由一系列读起来不错的代码文件组成的。它们需要拥有一致和顺畅的风格。读者要能确信,他们在一个源文件中看到的格式风格在其他文件中也是同样的用法。绝对不要用各种不同的风格来编写源代码,这样会增加其复杂度。
5.5 鲍勃大叔的格式规则¶
- 我个人使用的规则相当简单,如代码清单5-6所示。可以把这段代码看作是展示如何把代码写成最好的编码标准文档的范例。
6. 对象和数据结构¶
将变量设置为私有(private)有一个理由:我们不想其他人依赖这些变量。我们还想在心血来潮时能自由修改其类型或实现。那么,为什么还是有那么多程序员给对象自动添加赋值器和取值器,将私有变量公之于众、如同它们根本就是公共变量一般呢?
6.1 数据抽象¶
- 隐藏实现并非只是在变量之间放上一个函数层那么简单。隐藏实现关乎抽象! 类并不简单地用取值器和赋值器将其变量推向外间,而是曝露抽象接口,以便用户无需了解数据的实现就能操作数据本体。
- 我们不愿曝露数据细节,更愿意以抽象形态表述数据。这并不只是用接口和/或赋值器、取值器就万事大吉。要以最好的方式呈现某个对象包含的数据,需要做严肃的思考。傻乐着乱加取值器和赋值器,是最坏的选择。
6.2 数据、对象的反对称性¶
- 对象把数据隐藏于抽象之后,曝露操作数据的函数。数据结构曝露其数据,没有提供有意义的函数。回过头再读一遍。留意这两种定义的本质。它们是对立的。这种差异貌似微小,但却有深远的含义。
- 对象与数据结构之间的二分原理:
- 过程式代码(使用数据结构的代码)便于在不改动既有数据结构的前提下添加新函数。面向对象代码便于在不改动既有函数的前提下添加新类。
- 反过来也能说通:过程式代码难以添加新数据结构,因为必须修改所有函数。面向对象代码难以添加新函数,因为必须修改所有类。
6.3 得墨忒耳律¶
- 著名的得墨忒耳律(The Law of Demeter)认为:模块不应了解它所操作对象的内部情形。如前面所说,对象隐藏数据,曝露操作。这意味着对象不应通过存取器曝露其内部结构,因为这样更像是曝露而非隐藏其内部结构。
1. 火车失事
- 这类代码常被称作火车失事,因为它看起来就像是一列火车。这类连串的调用通常被认为是肮脏的风格应该避免。
- 属性访问器函数的使用把问题搞复杂了。如果像下面这样写代码,我们大概就不会提及对得墨忒耳律的违反。
- 如果数据结构只简单地拥有公共变量,没有函数而对象则拥有私有变量和公共函数,这个问题就不那么混淆。然而有些框架和标准甚至要求最简单的数据结构都要有访问器和改值器。
2. 混杂
- 此类混杂增加了添加新函数的难度,也增加了添加新数据结构的难度,两面不讨好。应避免创造这种结构。它们的出现,展示了一种乱七八糟的设计,其作者不确定——或者更糟糕,完全无视——他们是否需要函数或类型的保护。
3. 隐藏结构
- ctxt 隐藏了其内部结构,防止当前函数因浏览它不该知道的对象而违反得墨忒耳律。
6.4 数据传送对象¶
- 最为精练的数据结构是一个只有公共变量、没有函数的类。这种数据结构有时被称为数据传送对象,或 DTO(Data Transfer Objects)。
- Active Record 是一种特殊的 DTO 形式。它们是拥有公共(或可“bean”访问的)变量的数据结构,但通常也会拥有类似 save 和 find 这样的可浏览方法。
- 不幸经常发现开发者往这类数据结构中塞进业务规则方法,把这类数据结构当成对象来用。这是不智的行为,因为它导致了数据结构和对象的混杂体。
6.5 小结¶
- 对象曝露行为,隐藏数据。便于添加新对象类型而无需修改既有行为,同时也难以在既有对象中添加新行为。数据结构曝露数据,没有明显的行为。便于向既有数据结构添加新行为,同时也难以向既有函数添加新数据结构。
- 在任何系统中,我们有时会希望能够灵活地添加新数据类型,所以更喜欢在这部分使用对象。另外一些时候,我们希望能灵活地添加新行为,这时我们更喜欢使用数据类型和过程。优秀的软件开发者不带成见地了解这种情形,并依据手边工作的性质选择其中一种手段。