09-10¶
9. 重新组织数据¶
9.1 拆分变量(Split Variable)¶
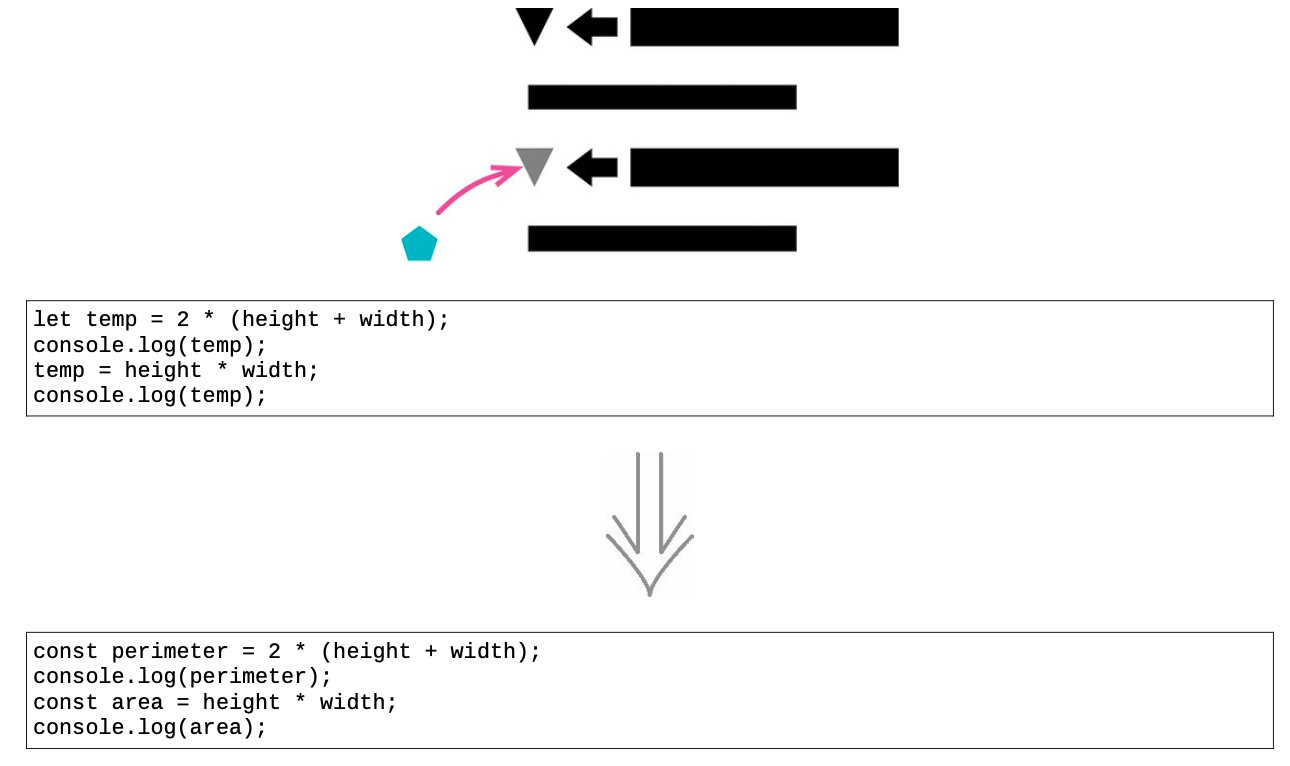
- 自然被多次赋值
变量有各种不同的用途,其中某些用途会很自然地导致临时变量被多次赋值。
- 承担多个责任的变量
如果变量承担多个责任,它就应该被替换(分解)为多个变量,每个变量只承担一个责任。同一个变量承担两件不同的事情,会令代码阅读者糊涂。
具体重构步骤
- 在待分解变量的声明及其第一次被赋值处,修改其名称;
如果稍后的赋值语句是“i=i+某表达式形式”,意味着这是一个结果收集变量,就不要分解它。结果收集变量常用于累加、字符串拼接、写入流或者向集合添加元素。
- 如果可能的话,将新的变量声明为不可修改;
- 以该变量的第二次赋值动作为界,修改此前对该变量的所有引用,让它们引用新变量;
- 测试;
- 重复上述过程。每次都在声明处对变量改名,并修改下次赋值之前的引用,直至到达最后一处赋值;
9.2 字段改名(Rename Field)¶
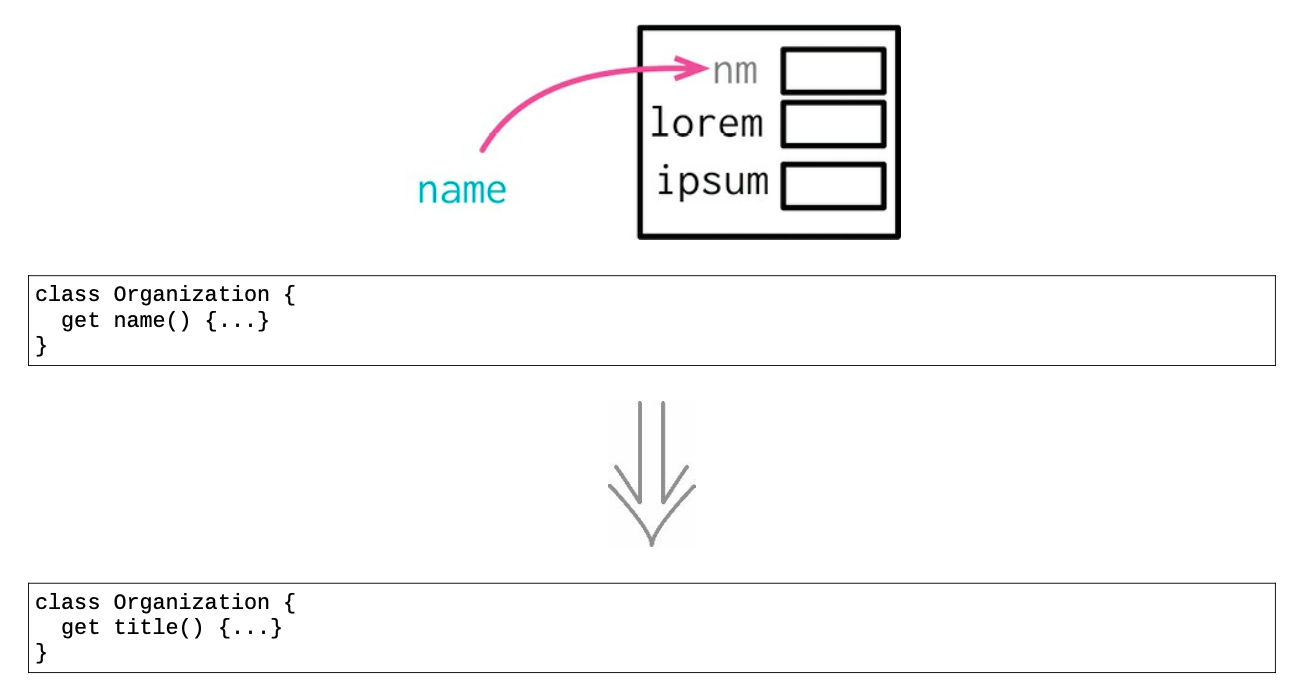
- 重要的命名
命名很重要,对于程序中广泛使用的记录结构,其中字段的命名格外重要。数据结构对于帮助阅读者理解特别重要。
- 保持数据结构的整洁
既然数据结构如此重要,就很有必要保持它们的整洁。一如既往地,若在一个软件上做的工作越多,对数据的理解就越深,所以很有必要把我加深的理解融入程序中。
具体重构步骤
- 如果记录的作用域较小,可以直接修改所有该字段的代码,然后测试。后面的步骤就都不需要了;
- 如果记录还未封装,请先使用封装记录;
- 在对象内部对私有字段改名,对应调整内部访问该字段的函数;
- 测试;
- 如果构造函数的参数用了旧的字段名,运用改变函数声明将其改名;
- 运用函数改名给访问函数改名;
9.3 以查询取代派生变量(Replace Derived Variable with Query)¶
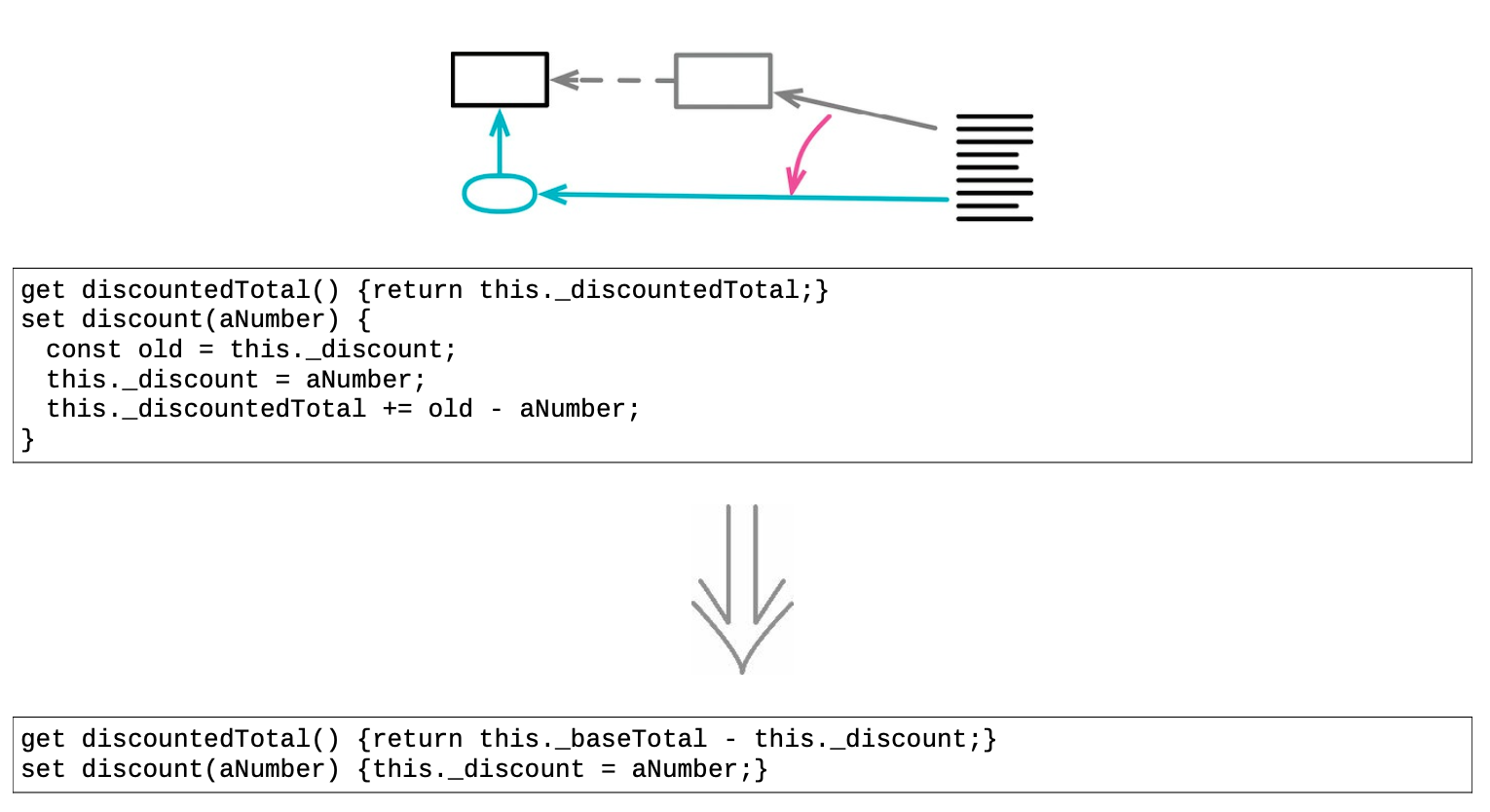
- 错误源头之可变数据
可变数据是软件中最大的错误源头之一。对数据的修改常常导致代码的各个部分以丑陋的形式互相耦合:在一处修改数据,却在另一处造成难以发现的破坏。
很多时候,完全去掉可变数据并不现实,但还是强烈建议:尽量把可变数据的作用域限制在最小范围。
- 可计算出的变量
有些变量其实可以很容易地随时计算出来。若能去掉这些变量,也会有助于消除可变性。
计算常能更清晰地表达数据的含义,而且也避免了“源数据修改时忘了更新派生变量”的错误。
- 两种不同的编程风格
“根据源数据生成新数据结构”的变换操作可以保持不变,即便可以将其替换为计算操作。
实际上,这是两种不同的编程风格:一种是对象风格,把一系列计算得出的属性包装在数据结构中;另一种是函数风格,将一个数据结构变换为另一个数据结构。
如果源数据会被修改,而必须负责管理派生数据结构的整个生命周期,那么对象风格显然更好。但如果源数据不可变,或者派生数据用过即弃,那么两种风格都可行。
具体重构步骤
- 识别出所有对变量做更新的地方。如有必要,用拆分变量分割各个更新点;
- 新建一个函数,用于计算该变量的值;
- 用引入断言断言该变量和计算函数始终给出同样的值;
如有必要,用封装变量将这个断言封装起来。
- 测试;
- 修改读取该变量的代码,令其调用新建的函数;
- 测试;
- 用移除死代码去掉变量的声明和赋值。
9.4 将引用对象改为值对象(Change Reference to Value)¶
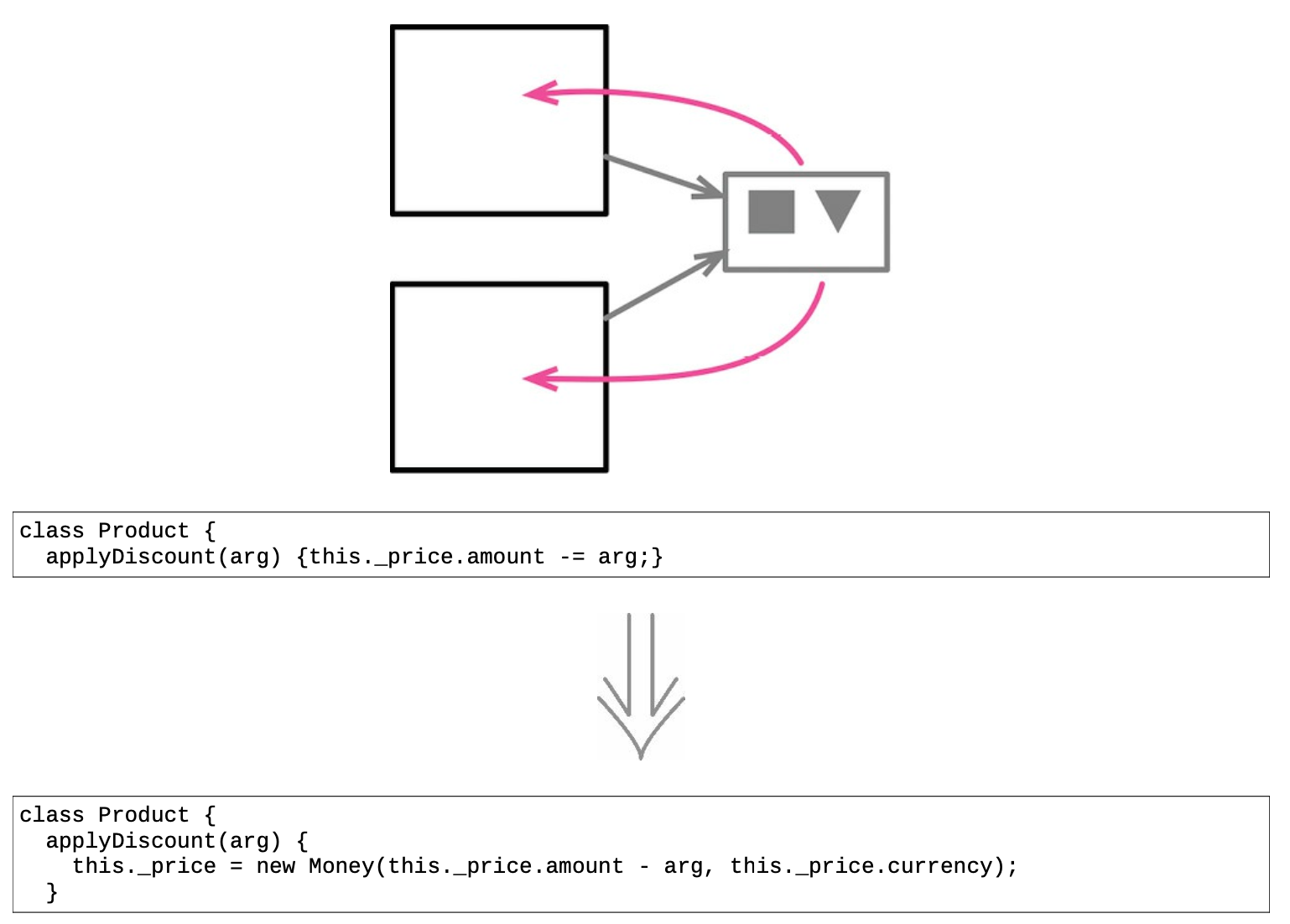
- 引用对象与值对象的差异
在把一个对象(或数据结构)嵌入另一个对象时,位于内部的这个对象可以被视为引用对象,也可以被视为值对象。
两者最明显的差异在于如何更新内部对象的属性:如果将内部对象视为引用对象,在更新其属性时,我会保留原对象不动,更新内部对象的属性;如果将其视为值对象,我就会替换整个内部对象,新换上的对象会有我想要的属性值。
- 更容易理解的值对象不可变
值对象通常更容易理解,主要因为它们是不可变的。
一般说来,不可变的数据结构处理起来更容易。可放心地把不可变的数据值传给程序的其他部分,而不必担心对象中包装的数据被偷偷修改。可在程序各处复制值对象,而不必操心维护内存链接。
值对象在分布式系统和并发系统中尤为有用。
- 共享对象的修改
在几个对象之间共享一个对象,以便几个对象都能看见对共享对象的修改,那么这个共享的对象就应该是引用。
具体重构步骤
- 检查重构目标是否为不可变对象,或者是否可修改为不可变对象;
- 用移除设值函数逐一去掉所有设值函数;
- 提供一个基于值的相等性判断函数,在其中使用值对象的字段;
大多数编程语言都提供了可覆写的相等性判断函数。通常你还必须同时覆写生成散列码的函数。
9.5 将值对象改为引用对象(Change Value to Reference)¶
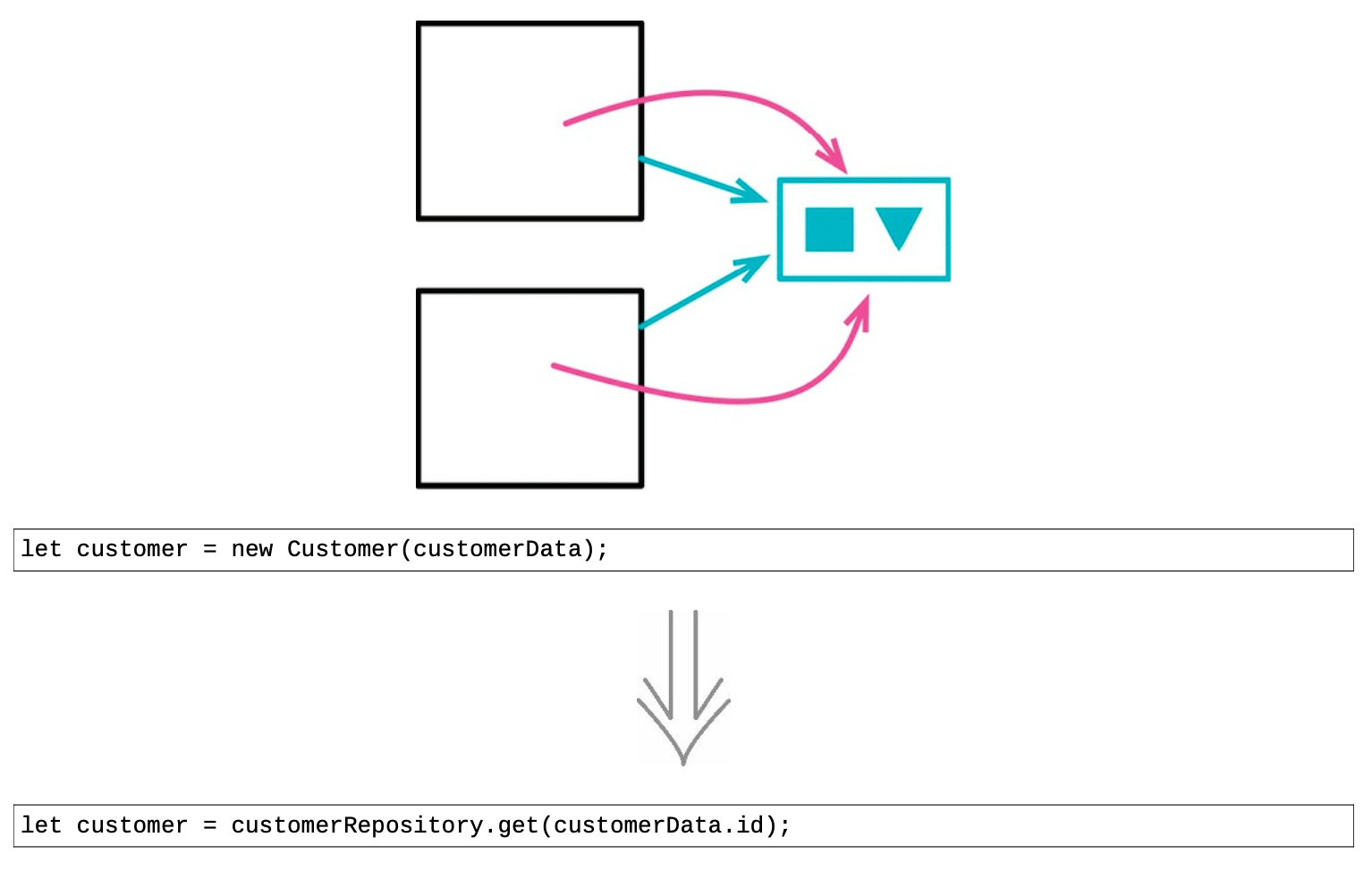
- 复制多次带来的内存问题
过多的数据复制有可能会造成内存占用的问题,但就跟所有性能问题一样,这种情况并不常见。
- 复制多份的局限
如果共享的数据需要更新,将其复制多份的做法就会遇到巨大的困难。
此时必须找到所有的副本,更新所有对象。只要漏掉一个副本没有更新,就会遭遇麻烦的数据不一致。
- 某种形式的仓库
把值对象改为引用对象会带来一个结果:对于一个客观实体,只有一个代表它的对象。
这通常意味着我会需要某种形式的仓库,在仓库中可以找到所有这些实体对象。只为每个实体创建一次对象,以后始终从仓库中获取该对象。
具体重构步骤
- 为相关对象创建一个仓库(如果还没有这样一个仓库的话);
- 确保构造函数有办法找到关联对象的正确实例;
- 修改宿主对象的构造函数,令其从仓库中获取关联对象。每次修改后执行测试。
10. 简化条件逻辑¶
10.1 分解条件表达式(Decompose Conditional)¶
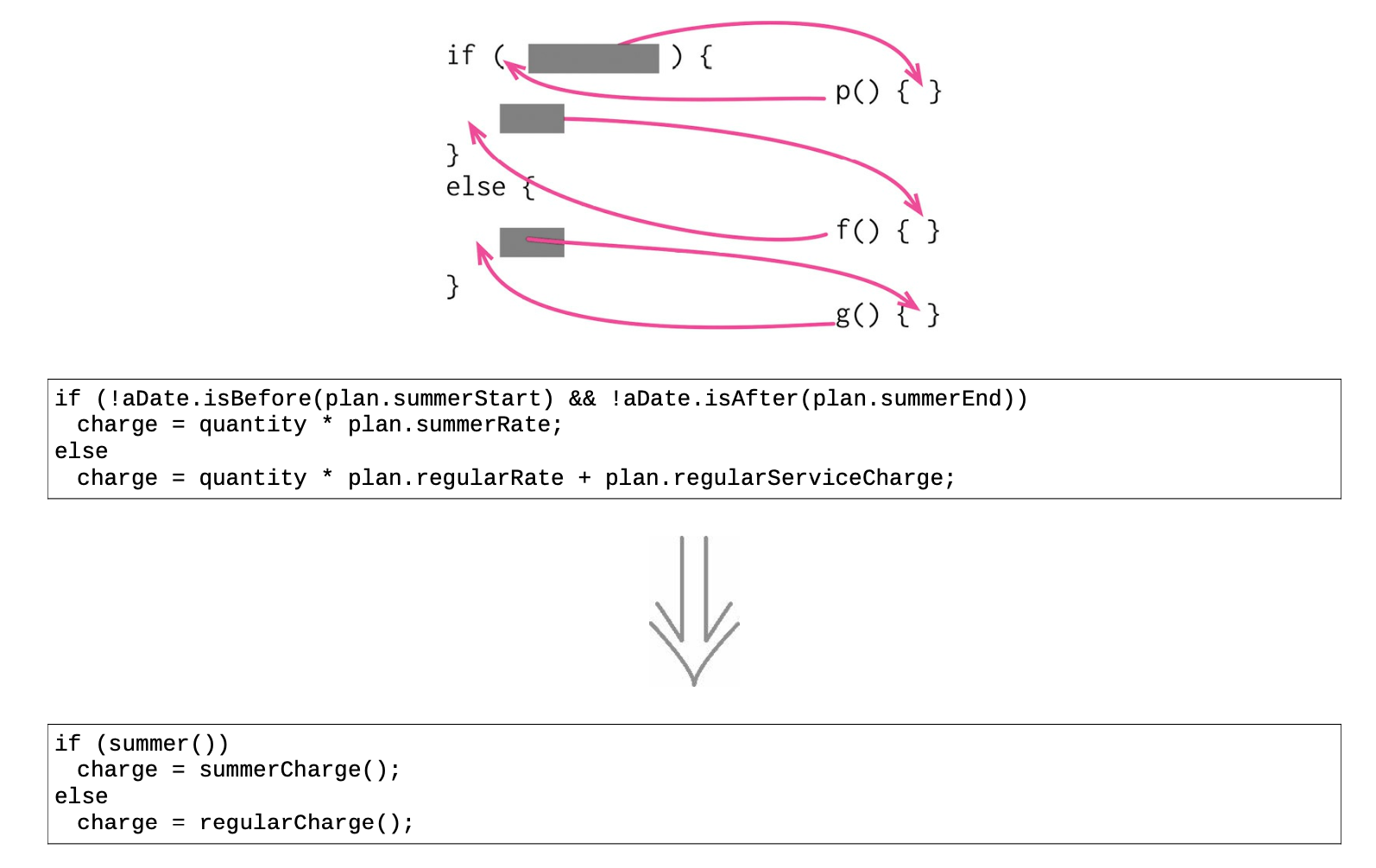
- 复杂条件逻辑带来的复杂性
程序之中,复杂的条件逻辑是最常导致复杂度上升的地点之一。必须编写代码来检查不同的条件分支,根据不同的条件做不同的事,然后就会得到一个相当长的函数。
大型函数本身就会使代码的可读性下降,而条件逻辑则会使代码更难阅读。
- 分解为多个独立的函数
和任何大块头代码一样,可将它分解为多个独立的函数,根据每个小块代码的用途,为分解而得的新函数命名,并将原函数中对应的代码改为调用新函数,从而更清楚地表达自己的意图。
对于条件逻辑,将每个分支条件分解成新函数还可以带来更多好处:可以突出条件逻辑,更清楚地表明每个分支的作用,并且突出每个分支的原因。
具体重构步骤
- 对条件判断和每个条件分支分别运用提炼函数手法。
10.2 合并条件表达式(Consolidate Conditional Expression)¶
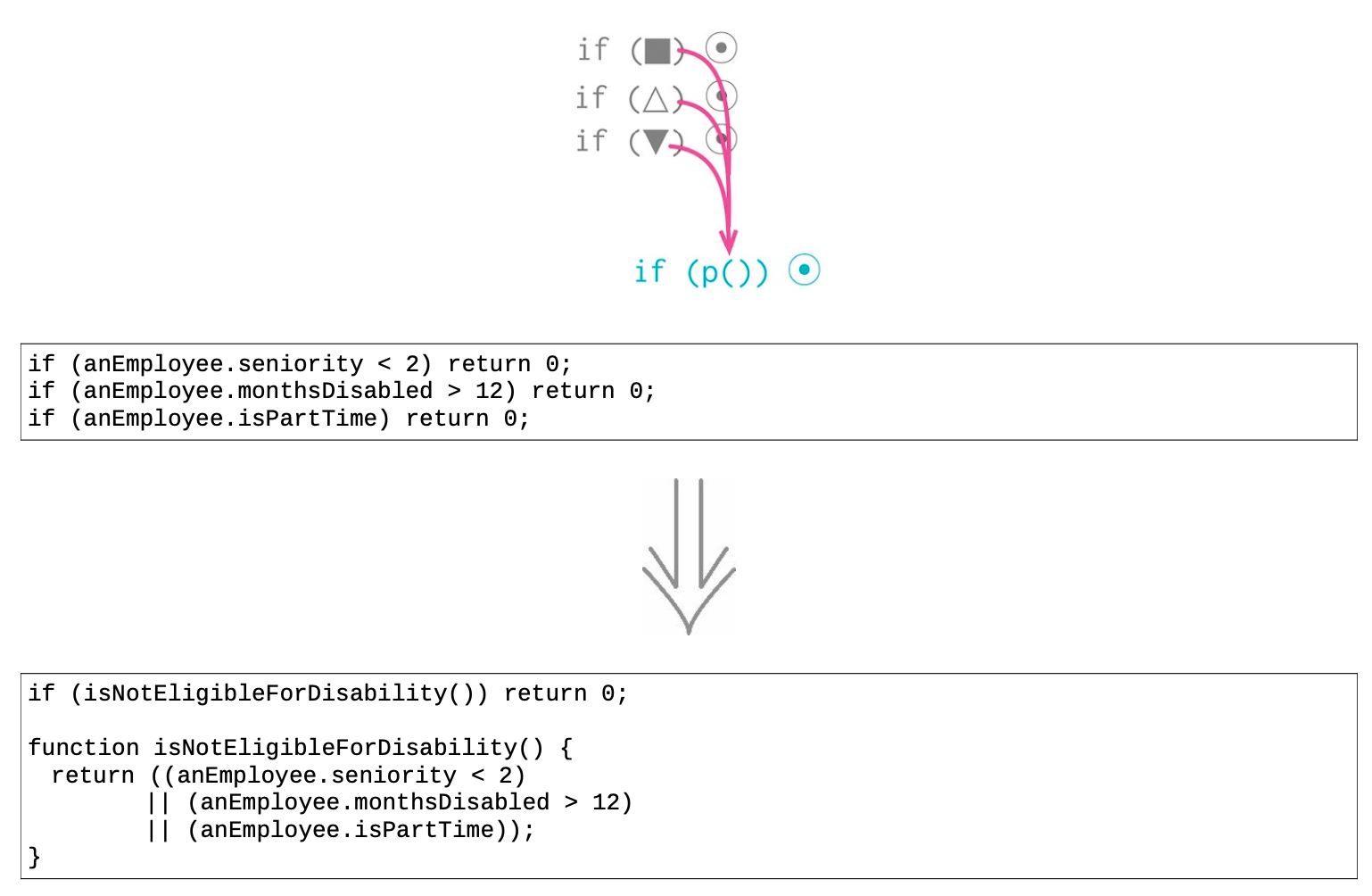
- 逻辑或和逻辑与
有时会发现这样一串条件检查:检查条件各不相同,最终行为却一致。如果发现这种情况,就应该使用“逻辑或”和“逻辑与”将它们合并为一个条件表达式。
- 提炼函数解释行为
将检查条件提炼成一个独立的函数对于厘清代码意义非常有用,因为它把描述“做什么”的语句 换成了“为什么这样做”。
- 不合并的理由
条件语句的合并理由也同时指出了不要合并的理由:若我认为这些检查的确彼此独立,的确不应该被视为同一次检查,我就不会使用本项重构。
具体重构步骤
- 确定这些条件表达式都没有副作用;
如果某个条件表达式有副作用,可以先用将查询函数和修改函数分离处理。
- 使用适当的逻辑运算符,将两个相关条件表达式合并为一个;
顺序执行的条件表达式用逻辑或来合并,嵌套的if语句用逻辑与来合并。
- 测试;
- 重复前面的合并过程,直到所有相关的条件表达式都合并到一起;
- 可以考虑对合并后的条件表达式实施提炼函数;
10.3 以卫语句取代嵌套比条件表达式(Replace Nested Conditional with Guard Clause)¶
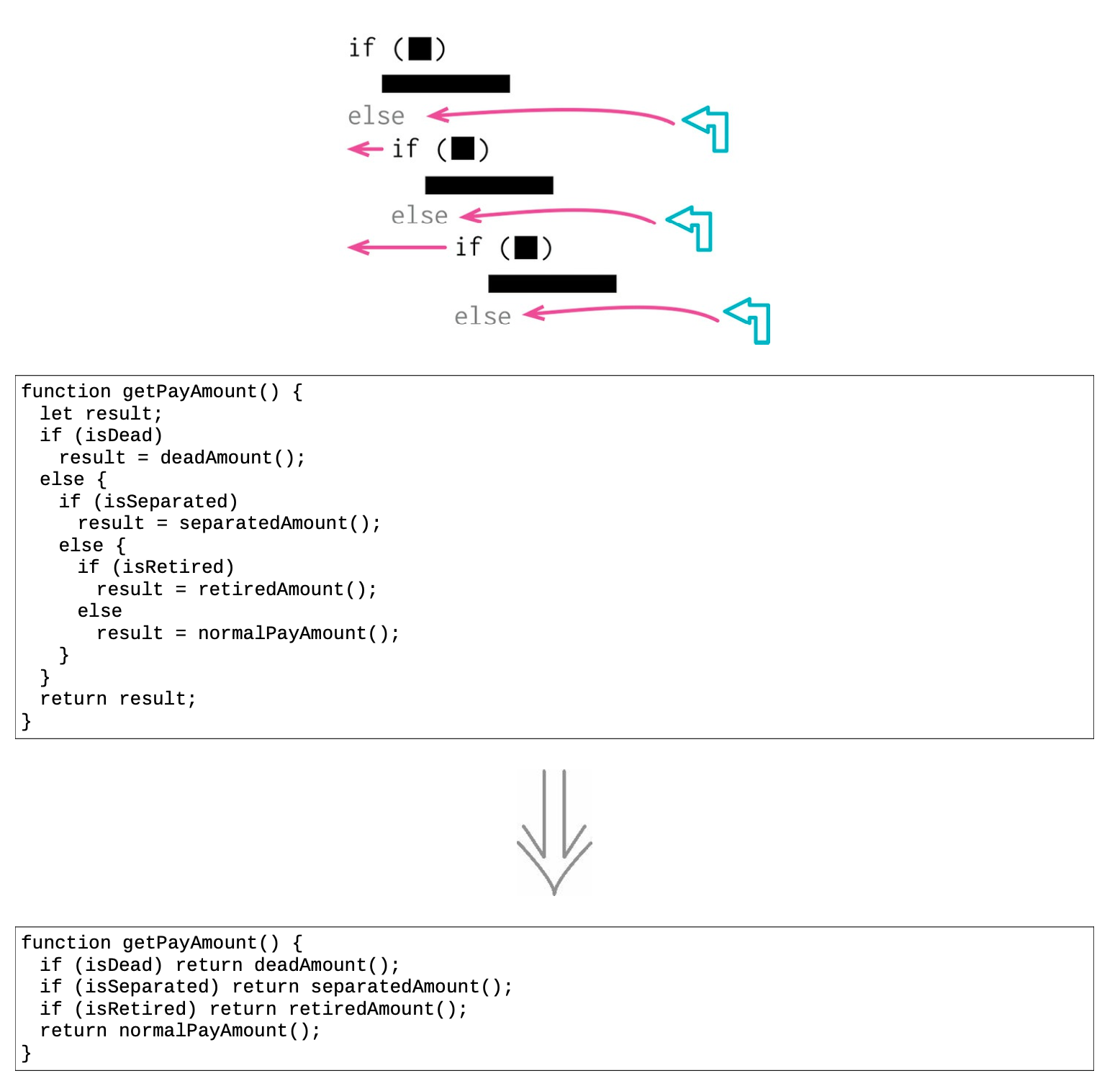
- 条件表达式的风格
条件表达式通常有两种风格:第一种风格是两个条件分支都属于正常行为;第二种风格则是只有一个条件分支是正常行为,另一个分支则是异常的情况。
这两类条件表达式有不同的用途,这一点应该通过代码表现出来。
如果两条分支都是正常行为,就应该使用形如 if else 的条件表达式;如果某个条件极其罕见,就应该单独检查该条件,并在该条件为真时立刻从函数中返回。这样的单独检查常常被称为“卫语句”(guard clauses)。
- 给某一条分支以特别的重视
如果使用if-then-else结构,你对if分支和else分支的重视是同等的。这样的代码结构传递给阅读者的消息就是:各个分支有同样的重要性。
卫语句就不同了,它告诉阅读者:“这种情况不是本函数的核心逻辑所关心的,如果它真发生了,请做一些必要的整理工作,然后退出。”
- 优先保持代码清晰
在我看来,保持代码清晰才是最关键的:如果单一出口能使这个函数更清楚易读,那么就使用单一出口;否则就不必这么做。
具体重构步骤
- 选中最外层需要被替换的条件逻辑,将其替换为卫语句;
- 测试;
- 有需要的话,重复上述步骤;
- 如果所有卫语句都引发同样的结果,可以使用合并条件表达式合并之;
10.4 以多态取代条件表达式(Replace Conditional with Polymorphism)¶
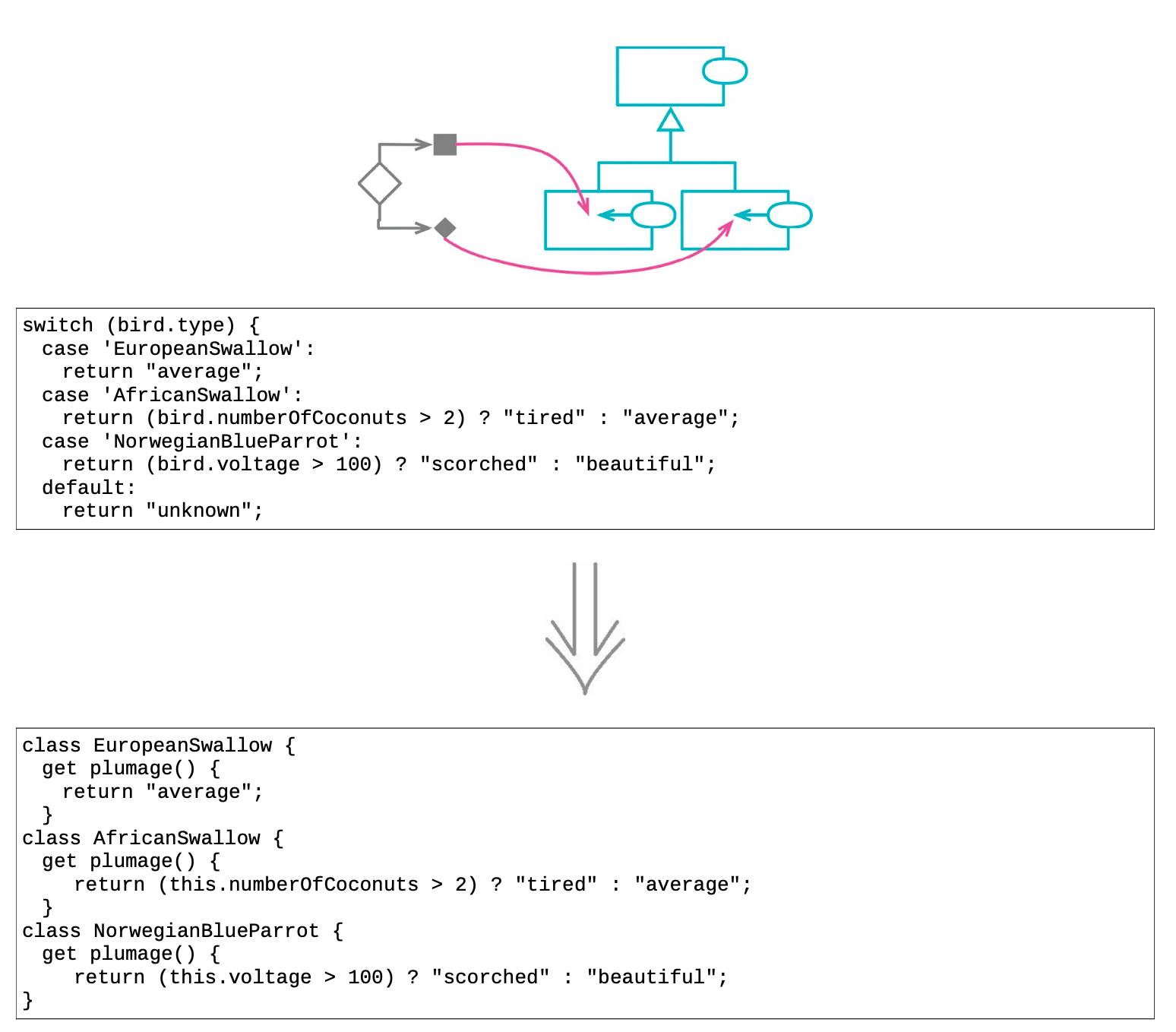
- 拆解复杂的条件逻辑
可将条件逻辑拆分到不同的场景(或者叫高阶用例),从而拆解复杂的条件逻辑。
这种拆分有时用条件逻辑本身的结构就足以表达,但使用类和多态能把逻辑的拆分表述得更清晰。
- 常见的构造场景
一种情况是可构造一组类型,每个类型处理各自的一种条件逻辑。最明显的征兆就是有好几个函数都有基于类型代码的switch语句。若是如此,则可针对switch语句中的每种分支逻辑创建一个类,用多态来承载各个类型特有的行为,从而去除重复的分支逻辑。
另一种情况是有一个基础逻辑,且其上又有一些变体。基础逻辑可能是最常用或最简单。可把基础逻辑放进超类,这样可首先理解该部分逻辑,暂时不管各种变体,然后将每种变体逻辑单独放进子类,来强调与基础逻辑的差异。
- 容易被滥用的多态
多态是面向对象编程的关键特性之一。跟其他一切有用的特性一样,它也很容易被滥用。但如果发现如前所述的复杂条件逻辑,多态是改善这种情况的有力工具。
具体重构步骤
- 如果现有的类尚不具备多态行为,就用工厂函数创建之,令工厂函数返回恰当的对象实例;
- 在调用方代码中使用工厂函数获得对象实例;
- 将带有条件逻辑的函数移到超类中;
如果条件逻辑还未提炼至独立的函数,首先对其使用提炼函数。
- 任选一个子类,在其中建立一个函数,使之覆写超类中容纳条件表达式的那个函数。将与该子类相关的条件表达式分支复制到新函数中,并对它进行适当调整;
- 复上述过程,处理其他条件分支;
- 在超类函数中保留默认情况的逻辑。或者,如果超类应该是抽象的,就把该函 数声明为abstract,或在其中直接抛出异常,表明计算责任都在子类中;
10.5 引入特例(Introduce Special Case)¶
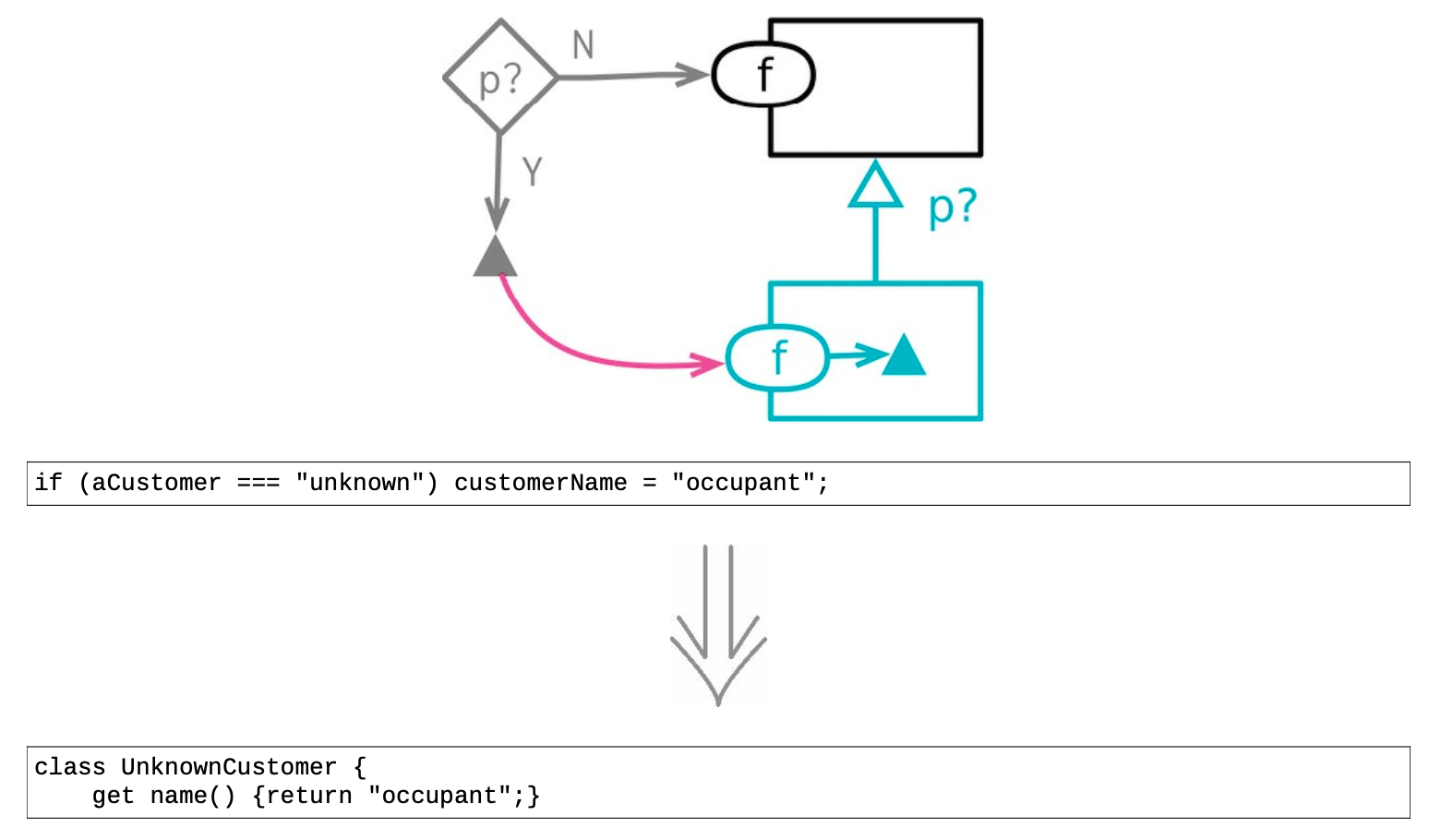
- 常见的重复代码
一种常见的重复代码是这种情况:一个数据结构的使用者都在检查某个特殊的值,并且当这个特殊值出现时所做的处理也都相同。如果发现代码库中有多处以同样方式应对同一个特殊值,可尝试把这个处理逻辑收拢到一处。
- 使用“特例”解决重复
处理这种情况的一个好办法是使用“特例”(Special Case)模式:创建一个特例元素,用以表达对这种特例的共用行为的处理。 这样可用一个函数调用取代大部分特例检查逻辑。
一个通常需要特例处理的值就是 null,这也是这个模式常被叫作“Null 对象”(Null Object)模式。
具体重构步骤
从一个作为容器的数据结构(或者类)开始,其中包含一个属性,该属性就是我们要重构的目标。容器的客户端每次使用这个属性时,都需要将其与某个特例值做比对。我们希望把这个特例值替换为代表这种特例情况的类或数据结构。
- 给重构目标添加检查特例的属性,令其返回false;
- 创建一个特例对象,其中只有检查特例的属性,返回true;
- 对“与特例值做比对”的代码运用提炼函数,确保所有客户端都使用这个新函数,而不再直接做特例值的比对;
- 将新的特例对象引入代码中,可以从函数调用中返回,也可以在变换函数中生成;
- 修改特例比对函数的主体,在其中直接使用检查特例的属性;
- 测试;
- 使用函数组合成类或函数组合成变换,把通用的特例处理逻辑都搬移到新建的特例对象中;
特例类对于简单的请求通常会返回固定的值,因此可以将其实现为字面记录(literal record)。
- 对特例比对函数使用内联函数,将其内联到仍然需要的地方;
10.6 引入断言(Introduce Assertion)¶
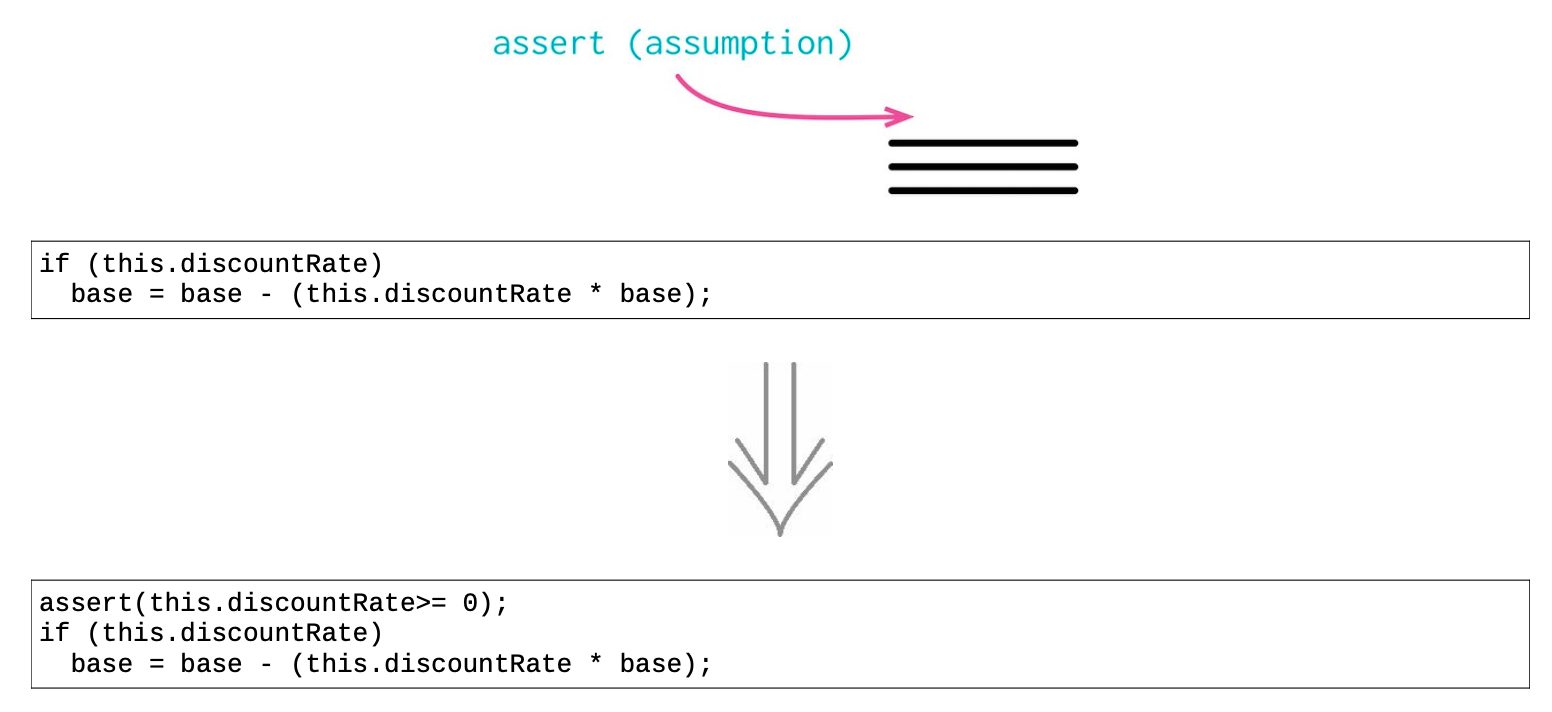
- 明确假设
某些假设通常并没有在代码中明确表现出来,必须阅读整个算法才能看出。有时程序员会以注释写出这样的假设,而我们可使用一种更好的技术——使用断言明确标明这些假设。
- 断言在交流中的价值
常看见有人鼓励用断言来发现程序中的错误。这固然是一件好事,但却不是使用断言的唯一理由。
断言是一种很有价值的交流形式——它们告诉阅读者,程序在执行到这一点时,对当前状态做了何种假设。另外断言对调试也很有帮助。而且,因为它们在交流上很有价值,即使解决了当下正在追踪的错误,我们还是倾向于把断言留着。
自测试的代码降低了断言在调试方面的价值,因为逐步逼近的单元测试通常能更好地帮助调试,但我们仍然看重断言在交流方面的价值。
具体重构步骤
- 如果你发现代码假设某个条件始终为真,就加入一个断言明确说明这种情况;
因为断言应该不会对系统运行造成任何影响,所以“加入断言”永远都应该是 行为保持的。